
想象一下:你花了11年成为联邦法官,每天研读数百页法律条文,自以为掌握了司法的”艺术”。突然,一个算法只用
3秒读完你花3天才能看完的案卷,然后告诉你:”这个案子会败诉,准确率比你高2倍。”这不是科幻,这是巴西联邦法院
正在上演的真实剧情。当22位资深法官和书记官的预测被深度学习模型按在地上摩擦时,我们不得不问:司法的尊严,
还能靠”人类直觉”维系多久?
💻 方法的基本信息
- 核心思想👋
用自然语言处理(NLP)技术”阅读”一审判决书的全文,通过深度学习模型自动提取法律事实、争议焦点和裁判逻辑,预测上诉结果。本质上,是让AI学会”像法官一样思考”,但比法官更快、更准、更不知疲倦。 - 独特价值
· 颠覆性对比:首次在真实司法场景中,将AI与在职法官直接PK,而非仅与历史数据对比
· 大规模实战:基于61万份真实上诉案卷训练,不是实验室玩具
· 跨语言突破:针对葡萄牙语法律文本优化,攻克了非英语NLP的”第二梯队”难题
· 完全开源:公开数据集(BrCAD-5)和代码,让全球研究者都能”审判”这个”AI法官”
💡 关键产出
- 方法的操作过程
· 应用原则
文本即数据:将法律判决书视为非结构化文本数据,而非神圣不可侵犯的”司法文书”
端到端学习:不依赖人工提取法律要件,让模型自己发现”胜诉/败诉”的语言模式
人机对抗验证:只有能击败人类专家的模型,才有资格进入司法系统
· 操作步骤
Step 1:数据构建
收集巴西第5联邦区法院2008-2021年765,602份上诉案件
⬇️
清洗、脱敏、标注结果(维持原判/改判)
⬇️
划分训练集(612,961份)与测试集(152,641份)
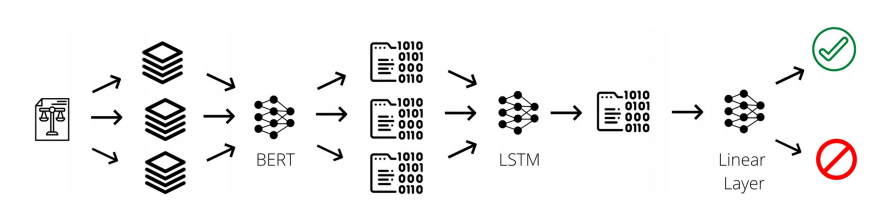
Step 2:模型训练(三驾马车)
ULMFiT:基于葡萄牙语维基百科预训练,再微调法律文本
⬇️
BERT+LSTM:用BERT提取语义特征,LSTM捕捉长文本依赖
⬇️
Big Bird:处理超长文档(判决书常超数千词)
Step 3:人类基准测试
招募22位在职联邦法官/书记官(平均从业11年)
⬇️
每人随机评估5-56份案卷,仅基于一审判决书预测上诉结果
⬇️
采用MCC指标避免类别不平衡偏差(维持原判占78%)
Step 4:对抗评估
在相同690份案卷上,比较人类与模型的预测一致性
⬇️
统计显著性检验(99%置信区间)
· 数据分析方法
- Matthews相关系数(MCC):综合准确率、召回率的平衡指标
- 时间漂移检测:验证模型在法律环境变化时的稳定性
- Fisher r-to-z变换:计算置信区间,确保统计严谨性
⚠️方法的应用启示
司法资源匮乏:巴西法院积压案件超8000万件,AI可优先筛选”无意义上诉”
法律咨询公司:为客户提供”上诉胜率预测”,定价策略更精准
立法评估:预测新法条可能引发的诉讼潮,辅助政策制定
教育领域:法学生可用AI模拟法庭,训练辩论策略
🧠个人思考:细思极恐的悖论
如果AI比法官更准,法官存在的意义是什么?维护正义,还是维持幻觉?
这篇论文最讽刺的是:模型表现最好的ULMFiT(一种RNN架构),恰恰是NLP领域被Transformer”淘汰”的”过气技术”。这意味着,司法预测不需要最前沿的GPT-4,一个”过时”模型就能碾压人类专家。这是否说明,法律裁判本质上是模式识别,而非高深智慧?
🙋值得探讨的新问题
1. 算法黑箱与司法透明:模型说”会败诉”,但不解释为什么,当事人能接受吗?
2. 数据偏见陷阱:训练数据来自历史判决,如果历史本身充满种族/阶层偏见,AI会”学习”并放大这种不公吗?
3. 法官的”算法依赖症”:如果法官开始依赖AI预测,司法独立是否会沦为”算法附庸”?
4. 中国场景:我们的”类案推送”系统已运行多年,但从未公开与法官的PK数据。是不敢,还是不能?
论文基本信息
GB/T 7714格式:
Jacob de Menezes-Neto E, Clementino M B M. Using deep learning to predict outcomes of legal appeals better than human experts: A study with data from Brazilian federal courts[J]. PLOS ONE, 2022, 17(7): e0272287.
APA格式(第7版):
Jacob de Menezes-Neto, E., & Clementino, M. B. M. (2022). Using deep learning to predict outcomes of legal appeals better than human experts: A study with data from Brazilian federal courts. PLOS ONE , 17 (7), Article e0272287. https://doi.org/10.1371/journal.pone.0272287
鑫烨对巴西联邦法院这项研究的剖析非常透彻,尤其点出了ULMFiT这种“过时”模型反而胜出的反直觉现象,这恰恰揭示了法律裁判中模式识别的本质。顺着这个思路,如果司法预测的本质是模式匹配,那么当法律条文或社会价值观发生重大变迁时,模型基于历史数据习得的模式是否会成为阻碍司法进步的“惯性锁”?换句话说,我们如何设计一种机制,让AI既能高效预测,又能主动识别并适应法律精神的演进?
谢谢老师的提问。
我觉得一是可以优化AI审判系统,比如过时的案例自动降权,新判例优先学习,就像手机系统定期更新。二是像我们的AI平台一样设”反对派”:专门训练一个AI唱反调。主流AI说”维持原判”,反对派必须找出”应该改判”的理由。两AI打架,人类拍板。三是设置一个底线:当AI预测和宪法精神冲突时,自动亮红灯,强制人类介入。AI可以建议,但价值判断的按钮永远在人手里。所以AI不能代替人类法官,AI更适合当”超级助理”,整理案卷、找相似案例、提醒风险,但敲锤子的只能是人类。效率交给算法,良心留给法官。
AI能替代机械裁判预测,但司法里的价值权衡、人情温度、自由裁量,恰恰是机器没法复刻的。未来不是AI取代法官,而是人类法官要从繁琐阅卷、重复预判里解放出来,把精力留在真正需要思辨和良知的核心环节。
这个帖子写得很有冲击力,层层递进,尤其把“过气模型碾压人类专家”这个反差点得很透,读起来确实细思极恐。
我比较好奇一点:测试用的是690份案卷,22位法官每人只评估了5到56份,这个样本量和任务分配方式会不会把“人类表现”拉低了?毕竟现实中的法官不是只看一审判决书就下结论的,二审还有庭审、新证据、合议这些环节。想知道论文里有没有讨论这个“人机对抗”的公平性问题。
把AI直接拉去和在职法官对打,比单纯跑模型指标更有说服力。不过我觉得也要冷静一点:预测“会不会改判”和真正“如何裁判”其实不是一回事,前者更像模式识别,后者还涉及价值判断和说理责任。方法上用大规模真实数据很扎实,但也正因为依赖历史判决,模型可能在无形中继承甚至放大既有偏见。对我来说最大的启发是:AI也许能成为高效的“筛选器”,但要取代法官,还远不只是准确率的问题。这项研究本身很有启发意义,但具体在实践中应该怎么应用还需要进一步的思考。
这篇关于 AI 挑战司法的文章的结果让我十分震撼,巴西法院用 61 万份案卷训练出的 AI,预测上诉结果比从业 11 年的法官还准、还快,甚至用 “过气” 模型就实现碾压对法官的碾压。让我不禁思考法官会不会成为AI时代继画家之后又一个被严重打击的行业?AI 确实能缓解案件积压、提升效率,但AI存在着算法黑箱、历史偏见放大、法官独立性被削弱等问题,如果这些问题没被解决就予以应用,其后果不堪设想。司法不只是对错判断,还包含人情、正义与价值权衡,不该被简化成模式识别。技术可以辅助审判,但绝不能替代人类法官的良知与裁量权。
看完这个案例,激发了我想要辩论的想法哈哈哈哈。这张巴西联邦法院的 AI 预测案例,确实把 “AI 能否代替法官” 这个问题推到了现实面前。但我认为,AI 模型的胜利,只在单一维度上碾压了法官:3 秒处理完 3 天的案卷,预测上诉结果的准确率是法官的 2 倍。它的核心工作,是 “预测” ,它只是根据历史案卷的文本特征,判断这个案子 “大概率会维持原判 或被推翻”,结合这个方法,本质上是一个高级的模式识别 + 分类任务。它无法做出价值判断、也无法解释 “为什么” 这么判,更无法处理法律之外的社会、伦理、人情因素。
当看到,用自然语言处理(NLP)技术”阅读”一审判决书的全文,通过深度学习模型自动提取法律事实、争议焦点和裁判逻辑,预测上诉结果。本质上,是让AI学会”像法官一样思考”,但比法官更快、更准、更不知疲倦。若效果符合标准,感觉到应该有很多人会失业。