
1. 导语
如果把课堂讨论中成千上万条学生同伴反馈交给 ChatGPT,它能不能像研究者一样判断学生是否真的在进行批判性思考?这篇文章的有趣之处不在于“神化”AI,而是用人工编码、ChatGPT 编码和机器学习评价指标进行对照,较为严肃地检验生成式 AI 在教育评价中的能力边界:它能做什么,不能做什么,以及哪里仍然需要人类判断。
2. 方法的基本信息
|
项目 |
内容 |
|
方法名称 |
基于既有批判性思维编码框架的 ChatGPT 辅助文本分类与评价方法 |
|
核心思想 |
将学生在线同伴反馈文本作为批判性思维表现的证据,先依据 Murphy 的批判性思维编码框架建立人工编码标准,再让 ChatGPT 对同一批文本进行编码,最后比较 ChatGPT 编码与人工编码的一致性和准确性。 |
|
方法定位 |
这不是一种全新的算法创新,而是一种“教育评价场景中的大语言模型应用验证方法”。它的重点是检验 ChatGPT 是否能在已有理论框架下承担部分文本评价任务。 |
|
独特价值 |
相比完全人工分析,它可以处理大规模开放性文本,减轻教师和研究者的编码负担;相比直接让 AI 自由评价,它又保留了明确的理论框架和人工编码基准,因此更适合教育研究中的严谨验证。 |
|
关键产出 |
每条学生反馈的批判性思维类别标签;一级指标和二级指标的 ChatGPT 编码结果;人工编码与 AI 编码的一致性;准确率、模糊率、错误率、Precision、Recall、F1 值和混淆矩阵等模型表现指标。 |
文章的总体发现比较克制:ChatGPT 对一级批判性思维维度有一定识别能力,但在更细颗粒度的二级维度上表现明显下降;同时,ChatGPT 编码准确性并没有明显受到学生原有批判性思维水平分组的影响。
3. 方法的操作过程
应用原则
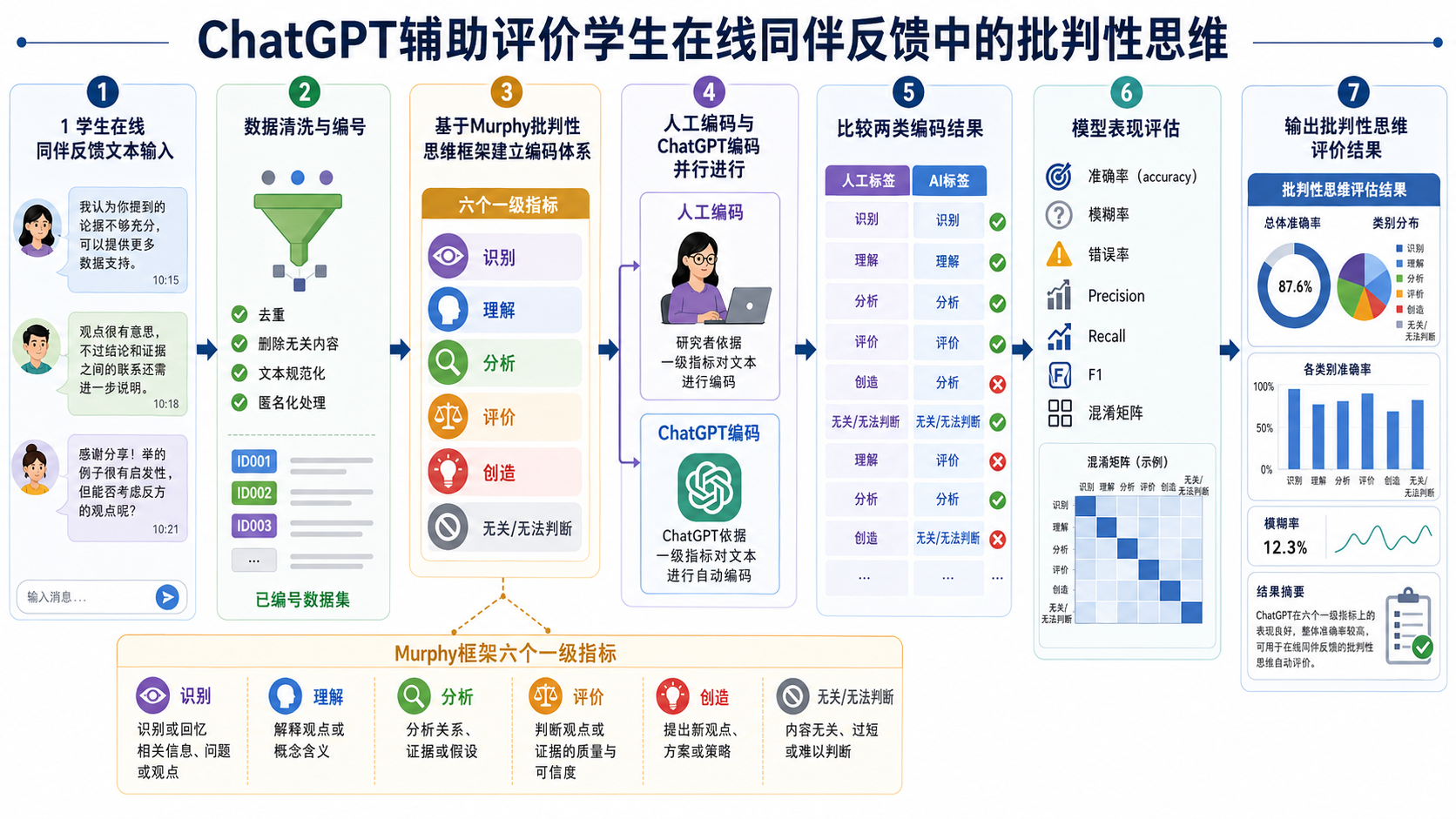
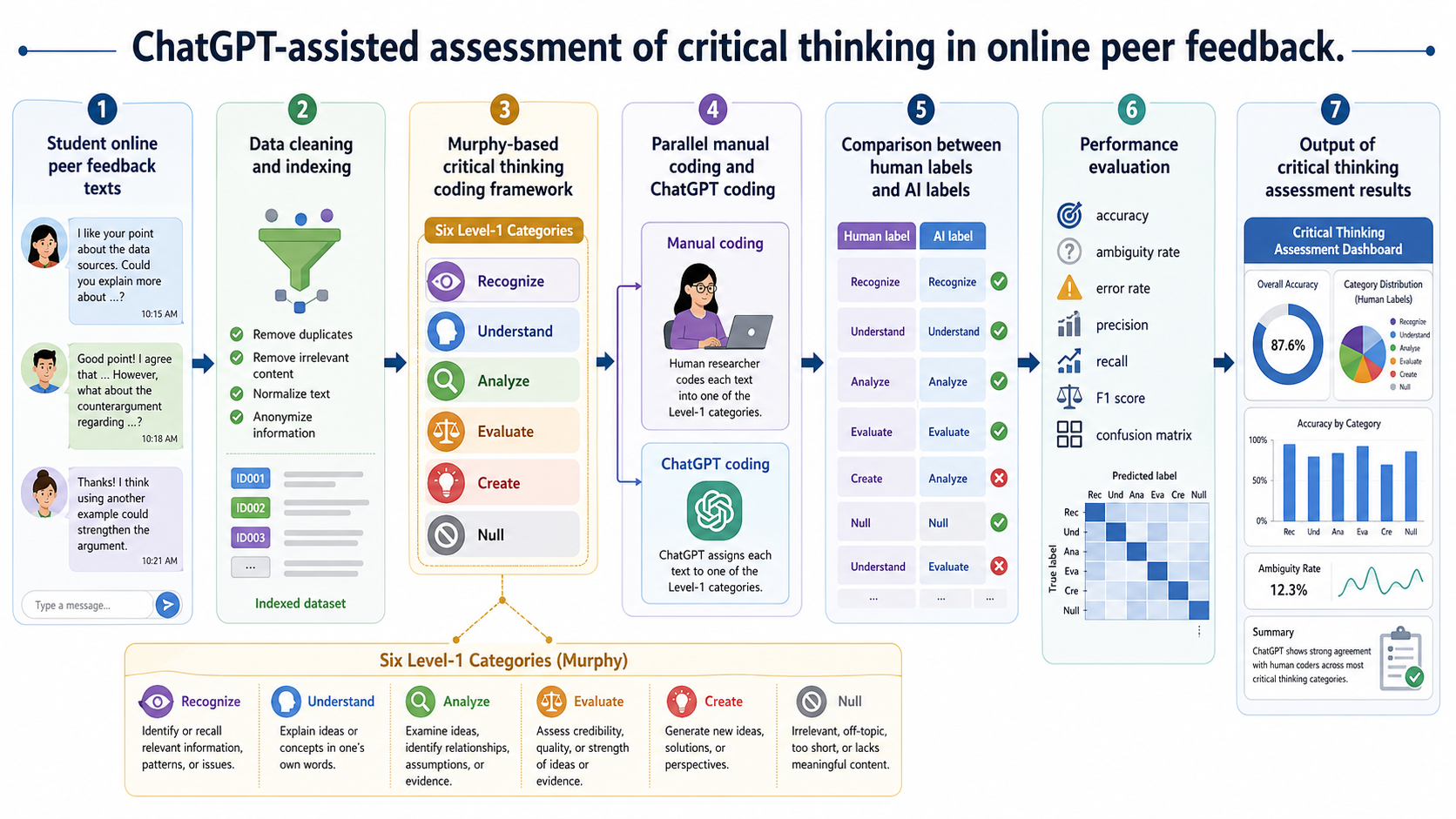
第一,必须先有明确的理论编码框架,不能直接让 ChatGPT “凭感觉”判断学生是否具有批判性思维。本文使用的是 Murphy 在线讨论批判性思维框架,并在原有框架基础上增加了 “Null” 类别,用于处理与主题无关或难以判断批判性思维的内容。最终编码框架包括 6 个一级指标:Recognize、Understand、Analyze、Evaluate、Create、Null,以及 25 个二级指标。
第二,人工编码仍然是基准。研究者邀请专家检查编码方案,两名研究者接受编码训练后独立编码,人工编码一致性 Cohen’s kappa 达到 0.941,说明人工编码结果具有较高可靠性。
第三,AI 评价不能只看“对/错”,还要考虑模糊性。文章采用了准确、模糊、错误三类判断,并进一步计算 Precision、Recall 和 F1,以避免把复杂文本判断过度简化为二元分类。
操作步骤
|
步骤 |
具体做法 |
|
1. 确定研究场景 |
研究对象为中国西部某高校 63 名教育技术学大二学生,课程为“发展与学习心理学”,研究发生在 2023 年春季学期。 |
|
2. 进行批判性思维前测 |
使用 CCTDI 量表评估学生批判性思维倾向,并分为高水平组、低水平组和混合组,每组 21 人。 |
|
3. 收集在线同伴反馈文本 |
学生在 QQ 群中围绕课程主题进行在线讨论和同伴反馈。研究从 2 万多条评论中随机抽取 800 条,经清洗后得到 780 条有效数据。 |
|
4. 建立编码框架 |
使用改编后的 Murphy 批判性思维编码框架,将学生反馈划分为 Recognize、Understand、Analyze、Evaluate、Create、Null 六类一级指标,并进一步细分为二级指标。 |
|
5. 人工编码 |
两名研究者依据编码框架独立编码全部数据,并进行一致性检验。 |
|
6. ChatGPT 编码 |
将清洗后的 780 条学生反馈文本按统一格式输入 ChatGPT,让其依据批判性思维编码框架输出一级和二级指标编码结果。 |
|
7. 编码结果复核 |
研究团队比较 ChatGPT 编码与人工编码,并采用 1、0、-1 三点评分:1 表示一致,0 表示模糊或部分相关,-1 表示不一致。 |
|
8. 模型表现分析 |
计算准确率、模糊率、错误率,以及 Precision、Recall、F1;同时绘制混淆矩阵,比较不同批判性思维水平学生组中的模型表现。 |
数据分析方法
本文的数据分析更接近“分类模型评价”思路。人工编码被视为参照标准,ChatGPT 编码被视为模型预测结果,然后计算分类准确性。一级指标上,ChatGPT 在三个学生组中的准确率均超过 70%;但二级指标明显较弱,高水平组为 23.0%,低水平组为 45.4%,混合组为 29.2%,说明它对粗粒度维度较可用,对细粒度判断仍不稳定。
总体模型表现方面,文章报告的总体 Precision、Recall 和 F1 大致在 0.70 左右,说明 ChatGPT 具有一定分类能力,但远未达到可以完全替代人工编码的程度。尤其是 Create、Null 等类别表现不够稳定,这提示我们:AI 更适合作为初筛、辅助编码或大规模趋势分析工具,而不宜直接用于高风险、细颗粒度的学生能力评价。
4. 方法的应用启示
这篇文章的方法适合用于大规模文本型学习过程数据分析,例如在线讨论、同伴互评、反思日志、开放式问答、课程论坛发言等。前提是研究者已经有较成熟的理论框架或编码表,否则 ChatGPT 的输出很容易变成“看似合理但缺乏标准”的主观判断。
我的看法是,这篇文章的方法价值主要在于“验证 AI 能否辅助教育评价”,而不是证明“ChatGPT 已经可以替代教师或研究者”。它比较适合做一级类别判断、趋势分析、初步筛选和辅助编码;但如果要精细判断学生具体处于哪一种批判性思维子维度,仍需要人工复核。文章结果也正好说明了这一点:一级指标表现尚可,二级指标明显不稳。
值得进一步讨论的问题包括:如果换成 GPT-4 或更新模型,结果是否会显著提升?如果提供 few-shot 示例或更精细的提示词,二级指标表现是否会改善?不同学科、不同语言、不同文化背景下的学生反馈,ChatGPT 的判断是否同样可靠?更重要的是,当 AI 参与学生能力评价时,如何处理隐私保护、算法偏差、教师责任和评价公平性问题?
5. 论文基本信息
APA 格式
Tang, T., Sha, J., Zhao, Y., Wang, S., Wang, Z., & Shen, S. (2024). Unveiling the efficacy of ChatGPT in evaluating critical thinking skills through peer feedback analysis: Leveraging existing classification criteria. Thinking Skills and Creativity, 53, 101607. https://doi.org/10.1016/j.tsc.2024.101607
补充:
标签
选题关键词:生成式人工智能、ChatGPT、教育评价、批判性思维、在线同伴反馈、高等教育、学习分析
研究方法关键词:人机编码比较、文本分类、编码框架、同伴反馈分析、AI 辅助评价、实证研究
数据分析方法关键词:Cohen’s kappa、一致性检验、准确率、模糊率、错误率、Precision、Recall、F1 score、混淆矩阵
适用领域关键词:教育技术、学习科学、在线学习、形成性评价、学生过程性数据分析
邹烨对这篇文章方法设计中的“人工编码基准+AI对照”思路梳理得很清晰,尤其是注意到一级与二级指标的表现差异。顺着这个思路,如果我们将ChatGPT的编码结果作为“弱标签”来训练一个更轻量的分类器,会不会在保持可解释性的同时提升细粒度识别效率?此外,你提到的跨语言、跨学科迁移问题也很关键——不同文化下批判性思维表达方式差异显著,这种验证方法能否通过调整编码框架来适应?
谢谢ai助教的回复。我的思考时,ChatGPT这类大模型已经在质性研究编码和教育评价、教育反馈等文本表现方面表现的相对出色,并且生成内容可用性整体也比较高,但是也需要进一步审慎依靠人工评估,不能完全采纳ChatGPT的编码结果或者教育评价反馈,因为技术迭代的很快,GPT也在不断的迭代升级模型,从4.0到最近的5.5,但是我认为可以预见的是,将ChatGPT的编码结果作为“弱标签”来训练一个更轻量的分类器,例如做一个教育编码的智能体,还是很有前景或者价值的。另外,跨语言和跨学科问题也需要得到重视,仍需要更多的研究来评估llm生成内容对教育的可用性
很漂亮的配图
邹烨的分享很有趣,这篇其实是在尝试把 AI 请进考场,让它当阅卷老师,判的是”批判性思维”那种没法靠选择题打分的题。结果很有意思:ChatGPT 看大方向还行——这学生会不会分析、会不会推理,它能摸个大概;但你让它往细了说:到底哪里分析得好、哪里推理掉链子了,它就迷糊了,得靠更细的评分标准才行。更让我觉得有意思的是,它判分跟学生本身的水平没啥关系,不是学霸就更受待见,后进生就一定低分。AI 在这个维度上反倒是”公平”的。
谢谢,“它判分跟学生本身的水平没啥关系,不是学霸就更受待见,后进生就一定低分”这句话非常通俗易懂地解释了ChatGPT没有受到主观打分的一些影响,所以ChatGPT赋能教育评价以及洞察学生的批判性思维这点的价值是可以被挖掘的。不过研究也提出了颗粒度不够清晰以及仍然需要依靠人工评分为主,说明人的主体性还是依然重要的
这篇文章把LLM as annotators这个较为热门的方向拉到了教育评价的具体场景里做实证。而且老老实实用人工编码当基准,用Precision、Recall、F1这些硬指标去考ChatGPT。这种验证式的思路,本身就比很多直接下结论的讨论有说服力。
不过读完有两个地方让我有点疑惑:
第一,ChatGPT在这项任务里的能力有没有被推到上限?从描述我并没有看出来具体使用的prompt。或许使用高质量的prompt范式或者换个提示方式,结论会不会不一样?
第二,二级指标表现差,不一定是模型不行,可能是框架本身的问题。如果框架的二级指标之间本身就有较高相关性,那模型挣扎在模糊边界上就不奇怪了。当然,人工编码一致性 Cohen’s kappa 达到 0.941,也可能说明我多虑了。
第二个疑惑那里,0.941是人工编码一致性,是研究者作为评分的基准。ChatGPT用以预测批判性思维这个结果。晓峰提到的这个框架本身的问题确实值得思考,模型是固定的,ChatGPT的表现可能依赖prompt和框架的输入,所以仍然可能是人工的复现
这项研究将ChatGPT置于一个严格的验证框架下——以人工编码为标准、以分类模型指标为度量,系统检验了生成式AI在教育文本评价中的真实能力边界。结果清晰地告诉我们:ChatGPT在粗粒度的一级批判性思维维度上表现尚可(准确率超70%),但在细粒度的二级维度上显著下降(最低仅23%),这意味着在当前阶段,AI更适合作为大规模文本的预编码或辅助筛查工具,而不能替代人工完成高风险、精细化的学生思维评价。这种“用可量化的指标说话、既看到能力也看到局限”的方法论态度,适用于对大规模开放式文本进行分析,对教育技术领域引入大语言模型尤其具有参考价值。
这篇文章把LLM as an annotator 这个较为热门的方向拉到了教育评价的具体场景里做实证,而且老老实实用人工编码当基准,用Precision、Recall、F1这些硬指标去考ChatGPT。这种“验证式”的思路,本身就比很多直接下结论的讨论有说服力。
不过读完有两个地方让我有点疑惑:
第一,ChatGPT在这项任务里的能力有没有被推到上限?从描述看文章没有详细描述使用的prompt。对于prompt设计的合理性有待验证。或许使用更高质量的prompt或者prompt范式会带来更高的提升。
第二,二级指标表现差,不一定是模型不行,可能是框架本身的问题。如果框架的二级指标之间本身就有较高相关性,那模型挣扎在模糊边界上就不奇怪了。当然,人工编码一致性 Cohen’s kappa 达到 0.941,说明我可能多虑了。
这篇选题非常贴近当下教育技术的核心关切,不会过分吹捧,也不否定,而是以严谨对照的方式去检验生成式人工智能在教育评价中的真实能力,极具现实意义。我认为文章最大的创新在于把AI放在成熟的理论框架与高质量人工编码的双基准下验证,既发回来大模型处理大规模文本的效率优势,又坚定了教育研究的科学性与规范性,避免了AI自由评价带来的主观性风险。
这篇文章把LLM as an annotator 拉到了教育评价的具体场景里做实证,而且老老实实用人工编码当基准,用Precision、Recall、F1这些硬指标去考ChatGPT。这种“验证式”的思路,本身就比很多直接下结论的讨论有说服力。
不过读完有两个地方让我有点疑惑:
第一,ChatGPT在这项任务里的能力有没有被推到上限?从描述看文章没有详细描述使用的prompt。对于prompt设计的合理性有待验证。或许使用更高质量的prompt或者prompt范式会带来更高的提升。
第二,二级指标表现差,不一定是模型不行,可能是框架本身的问题。如果框架的二级指标之间本身就有较高相关性,那模型挣扎在模糊边界上就不奇怪了。当然,人工编码一致性 Cohen’s kappa 达到 0.941,说明我可能多虑了。
这篇研究使用ChatGPT对在线同伴反馈中的批判性思维进行编码,并与人工编码比较,采用精确率、召回率、F1值等指标评估性能,同时按学生批判性思维水平分组分析。方法设计清晰,量化手段规范,尤其关注了细粒度编码的挑战。但是我也有一个疑问,这个研究仅依赖单轮Few-shot提示,未尝试微调或提示工程优化。若能针对低准确率维度进行迭代提示优化,ChatGPT的细粒度评估性能是否可能显著提升?
邹同学分析的文章特别有趣,文章章的方法价值主要在于“验证 AI 能否辅助教育评价”,而不是证明“ChatGPT 已经可以替代教师或研究者”。它比较适合做一级类别判断、趋势分析、初步筛选和辅助编码;但如果要精细判断学生具体处于哪一种批判性思维子维度,仍需要人工复核。文章结果也正好说明了这一点:一级指标表现尚可,二级指标明显不稳
这篇研究做得挺扎实的,尤其喜欢它没有一味吹捧AI,而是老老实实对比人工编码和ChatGPT编码的差异。一级指标准确率还行,到了二级指标就明显下滑,这个发现很真实——说明粗线条的判断AI能帮上忙,但真要细抠认知层次,还是得靠人。好奇如果换成GPT-4加上few-shot示例,二级指标会不会有质的提升呢?