
1. 导语 🌟 随着大模型融入课堂,学生与AI导师的对话记录成了一座数据富矿。但你是否想过,这些看似日常的聊天日志背后,其实隐藏着学生自我调节学习(SRL)的关键密码?今天分享一篇25年发表在《Journal of Learning Analytics》上的论文,教你如何利用过程-动作认知网络分析(Process-Action ENA),让那些隐秘的学习策略无所遁形!🔍
2. 方法的基本信息 💡
- 核心思想:将经典的SRL理论框架与大语言模型(LLM)生成的真实对话日志相结合 。通过构建一个“过程-动作(Process-Action)”词典,将非结构化的对话数据,转化为结构化的学习动作代码 。
- 独特价值:突破了传统SRL研究依赖问卷自评或有声思维(think-aloud)的局限性 。它提供了一种全新的量化手段,利用生成式AI的交互数据来揭示学习环境中的动机和行为差异 。
- 关键产出:生成高度可视化的认知网络图(Epistemic Networks)和有向网络图(Ordered Networks) ,直观展现不同能力水平和学习增益学生在提问、反思、目标设定等行为上的路径差异 。
3. 方法的操作过程 🛠️
- 应用原则: 核心是基于苏格拉底式提问原则,即AI不直接提供答案,而是通过脚手架式的追问(scaffolded manner),旨在将复杂的概念拆解为渐进式的子问题,让学生在互动中自主经历“定义、搜寻、参与、反思”的认知循环 。

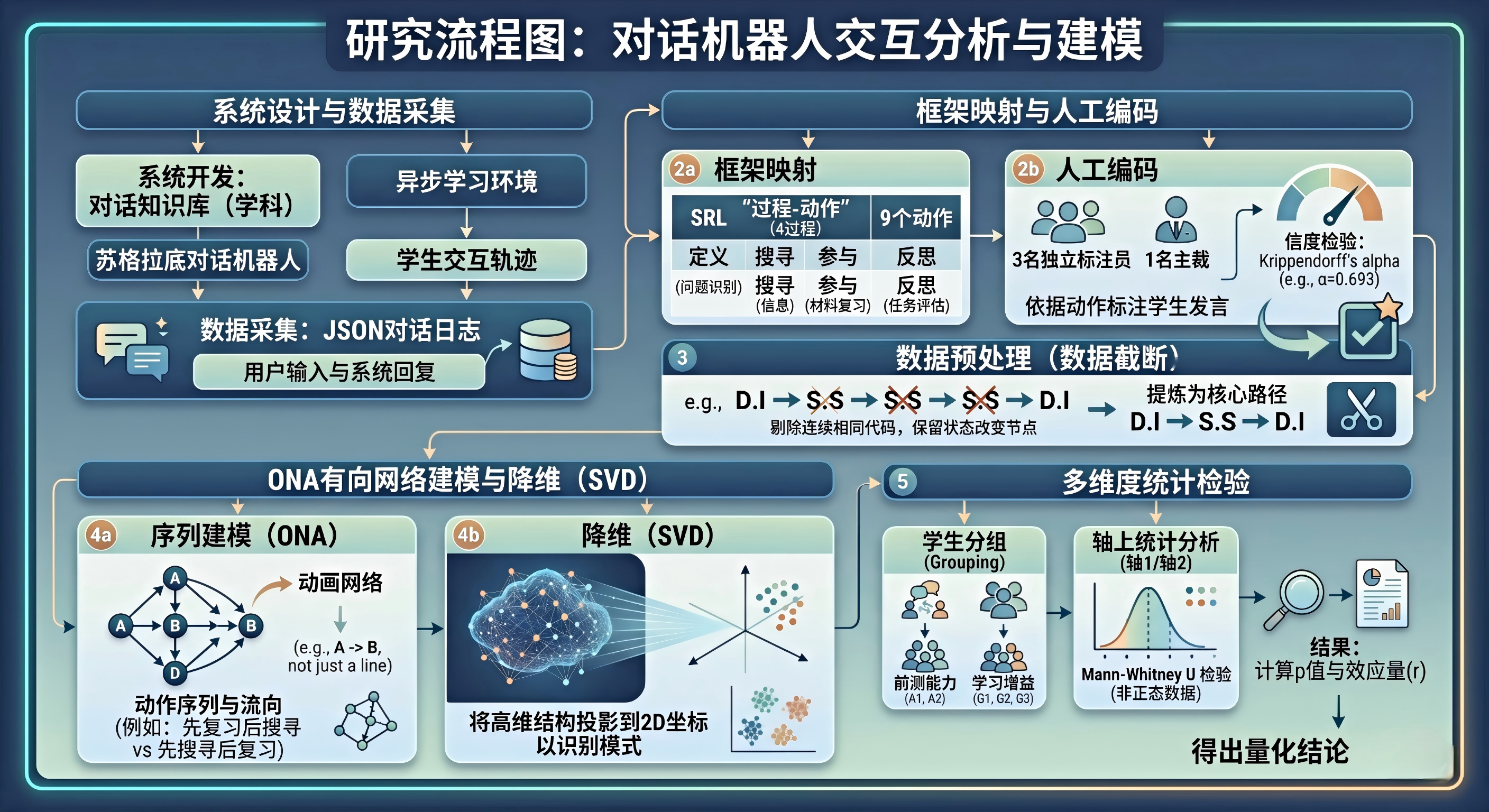
- 操作步骤与数据分析方法⚠️:
1️⃣ 系统搭建与数据采集 (System Design & Data Collection)
利用Streamlit等框架,结合GPT-4引擎,开发嵌入特定学科知识库(如统计学课程内容)的苏格拉底式聊天机器人 。该系统不仅能在后台存储每一句对话的JSON日志,还能记录学生在异步学习环境中的完整交互轨迹 。2️⃣ 构建框架与人工编码 (Framework & Coding)
a.框架映射: 采用精炼的SRL“过程-动作”框架,包含4大过程(定义、搜寻、参与、反思)和9大动作(如问题识别、搜寻信息、材料复习、任务评估等) 。
b.标注检验: 安排3名独立标注员和1名主裁对每一句学生发言进行“动作”贴标。使用Krippendorff’s alpha (本研究 alpha=0.693) 来验证多人编码的信度和一致性,这是保证后续数据分析科学性的基石 。3️⃣ 关键的数据截断预处理 (Data Truncation)
由于苏格拉底机器人的连续追问,学生常常会给出多句同质化的回复(例如连续出现“搜寻-搜寻”代码)。如果直接建立网络模型,会导致高频动作主导网络,掩盖真实的学习状态转移 。因此,必须剔除连续出现的相同代码,仅保留发生状态改变的节点(例如,将D.I ➔ S.S ➔ S.S ➔ D.I提炼为核心的跳跃路径D.I ➔ S.S ➔ D.I) 。4️⃣ ONA有向网络建模与降维 (Network Construction & SVD)
a.序列建模: 摒弃传统的无向认知网络(ENA),采用有向网络分析(ONA)。ONA不仅统计动作共现,还能捕捉动作发生的先后顺序和流向(例如准确区分“先复习后搜寻”与“先搜寻后复习”) 。
b.降维映射: ONA模型将动作间的共现权重转化为有向边,接着利用奇异值分解(SVD)进行降维处理,将高维的复杂拓扑结构投影到清晰的二维坐标系中,方便肉眼直观识别模式差异 。5️⃣ 多维度统计检验与比较 (Statistical Comparison)
依据前测能力(A1/A2组)和学习增益(G1/G2/G3组)将学生分群 。在降维后的坐标轴上,运用 Mann-Whitney U 检验(适用于非正态分布数据)计算组间差异的显著性(p值)和效应量(r值),从而得出精准的量化结论 。
4. 方法的应用启示 ✨
- 🎯 方法的适用情境: 该方法非常适合应用于混合式学习(Blended Learning)、异步在线课程以及任何引入了生成式AI(GenAI)作为辅导工具的教育场景 。当教育者或研究人员希望打开AI交互的“黑盒”,不再仅仅关注学生最终的学习成绩,而是想要动态追踪学生在遇到难题时是如何求助、如何反思、如何调整策略时,过程-动作认知网络分析能提供极其直观的数据支撑 。
- 💡 个人思考: 这篇论文最让我受启发的一点是它证明了“自我调节学习在AI时代是非线性的” 。传统的学习理论往往认为学生会按部就班地经历“计划-执行-反思”的循环,但在与AI的实时互动中,学生的策略切换非常碎片化和情境化 。例如,研究发现低能力学生更倾向于“先复习后搜索”的防御性学习姿态,而高能力学生则是“搜索与复习并进”的探索性姿态 。这提示我们,未来在设计教育AI的Prompt时,绝不能“一刀切” :对于低分学生,AI需要主动提供更强力的脚手架,引导他们走向深度的目标设定和内容组织;而对于高分学生,则应保持适当的开放度,鼓励他们持续进行高阶的SRL动作 。
- 🚀 值得探讨的新问题:
这篇研究也为未来的探索留下了极具吸引力的空白,非常值得大家在评论区讨论:
AI反向编码: 目前研究只对“学生的动作”进行了编码。如果我们把“AI机器人的回复策略”也纳入编码网络,分析特定的AI话术是如何触发学生特定的认知跃迁的,是否能彻底揭开人机协同学习的交互机制 ?
显性干预 vs. 隐性引导: 论文中的苏格拉底机器人只是在讨论学科知识(隐性引导)。如果开发一款直接教导学生“你现在应该设定目标了”或“你该反思了”的元认知干预机器人,网络图会发生怎样的剧变 ?
走向社会化学习: 当AI聊天机器人不再是一对一辅导,而是作为一个协作者加入到学生的小组合作学习中时,多主体间的认知网络(群体动力学)又该如何建模 ?
5. 论文基本信息 📚
Lai, J. W., Qiu, W., Thway, M., Zhang, L., Jamil, N. B., Su, C. L., Ng, S. S. H., & Lim, F. S. (2025). Leveraging Process-Action Epistemic Network Analysis to Illuminate Student Self-Regulated Learning with a Socratic Chatbot. Journal of Learning Analytics, 12(1), 32–49.
晓峰对过程-动作ENA的方法论梳理很清晰,特别关注了数据截断的必要性。不过,这里有一个潜在问题:连续同质化回复的剔除虽然避免了高频动作主导网络,但也可能丢失了学生坚持同一策略时的真实状态信息。例如,连续“搜寻-搜寻”可能反映学生持续探索而非停滞,这种删除是否过度简化了学习行为的非线性特征?另外,Krippendorff’s alpha为0.693,刚过可接受阈值,编码信度是否足够支撑后续复杂的ONA建模?
您这两个问题抓得太准了,刚好戳中了这项研究的核心漏洞。一刀切剔除连续重复动作,确实会抹掉学生学习的真实状态,不管是持续探索还是卡壳停滞,都被当成冗余数据删掉了,过度简化了学习行为的非线性特征。而0.693的alpha值刚踩编码信度的及格线,可整个研究的建模和结论全靠这套编码打底,信度不足,后续的分析和结论自然会打折扣。
晓峰这个分享真是太酷了! 我尤其喜欢你把AI课堂对话数据比喻成“数据富矿”,瞬间就拉近了读者与研究的距离。方法设计很精细,从动作编码、连续动作处理,到有向网络建模和降维,再到组间统计检验,每一步都体现了研究者对数据和学习过程的深度理解,保证了结果既科学又可解释。
在测量自我调节学习时,往往过度依赖事后的自陈量表或成本高昂的有声思维。这篇研究证明了生成式AI的交互日志本身就是一种高保真的过程性数据。通过过程-动作ENA将非结构化文本转化为结构化代码,再利用有向网络分析捕捉状态转移的序列特征,这种降维打击般的量化手段,让我们终于能以可视化的方式,直观地看到学生在认知过程中的非线性跳跃。
我看到论文中一个处理逻辑时如果学生多次出现搜索→搜索的转移,只会保留一次从搜索到其他状态的转移,这种操作会不会删除有意义的行为模式,比如学生重复搜索可能是遇到了困难
ENA与AI聊天日志结合,突破传统SRL问卷与有声思维的局限,用过程-动作编码、有向网络建模精准拆解学生学习行为路径。其揭示的AI环境下非线性SRL特征极具现实价值,也为因材施教的教育AI设计提供新思路。同时AI话术编码、群体认知网络建模等留白方向,也为人机协同学习研究开辟了新探索空间。
这篇关于过程 – 动作 ENA 的研究让我眼前一亮,我认为它真正打开了 AI 教育交互的 “黑箱”。它把学生和 AI 导师的对话日志转化为可量化、可可视化的认知网络,摆脱了传统学习分析只看结果、依赖问卷的局限。研究发现 AI 时代学习行为非线性、碎片化,不同水平学生策略差异显著,为因材施教提供了精准依据。这种方法既能追踪学习过程,又能指导 AI 辅导设计,兼顾理论深度与实践价值。未来若加入 AI 话术编码、显性元认知引导,还能进一步完善人机协同学习模型,对教育数字化转型极具启发意义。
这篇文章让我觉得很有启发,它没有只看AI辅导能不能提高成绩,而是关注学生和AI互动时到底用了哪些学习策略。过程-动作ENA把聊天记录变成可视化网络,能看出不同学生的提问、复习和反思路径。这个方法很适合分析AI课堂,但人工编码和数据处理方式也可能影响结果,需要谨慎解释。