一: 导语
为什么有的学生一直自信满满,有的却逐渐“认清现实”?
为什么同一门课,有人越学越有信心,有人却越来越低估自己?
这些差异,其实不是“平均趋势”能解释的。
潜在增长混合模型(LGMM),正是用来揭示这种“隐藏在群体中的不同发展轨迹”的强大工具。它不仅能看到变化,还能告诉我们——谁在怎么变,以及为什么变。
二: 方法的基本信息
📌 核心思想
LGMM(Latent Growth Mixture Model)是一种结合:
潜在增长模型(LGM)(分析变化趋势)
潜类别分析(LCA)(识别群体分类)
👉 一种纵向数据分析方法
🌟 独特价值
LGMM实现了三件关键事情:
看变化(动态)
个体随时间的发展轨迹(不是静态)
看差异(异质性)
同一群人中存在不同发展模式
自动分类(数据驱动)
模型自动识别“几类人”,而不是人为分组
📊 关键产出
LGMM最终会给你:
每一类人群:
截距(Intercept) → 初始水平
斜率(Slope) → 变化趋势
潜在类别(Classes)
每个人属于某类的概率(posterior probability)
📌 应用原则
必须是纵向数据(≥3个时间点)
同一变量重复测量(如成绩预期)
样本量相对较大(一般建议 N > 200)
🧩 操作步骤(论文中的流程)
Step 1:数据准备
多时间点跟踪数据(T1, T2, T3…)
同一指标(如成绩预期偏差)
Step 2:建立单组增长模型(LGCM)
检验:
截距是否显著
斜率是否显著
👉 判断是否存在个体差异
Step 3:建立混合模型(LGMM)
依次尝试:
2类、3类、4类模型
Step 4:确定最优类别数
关键指标:
SABIC / BIC ↓(越小越好)
Entropy ↑(>0.8 理想)
LMRT(p < .05 表示模型改进显著)
Step 5:轨迹解释与命名
例如论文中发现:
持续高乐观组(高截距 + 平稳)
下降组(高截距 + 负斜率)
现实稳定组(低截距 + 平稳)
Step 6:进一步分析
Logistic 回归 → 谁更可能属于某类?
ANOVA → 不同组结果差异
LGMM,看见学生的不同成长方式
三:LGMM方法流程图
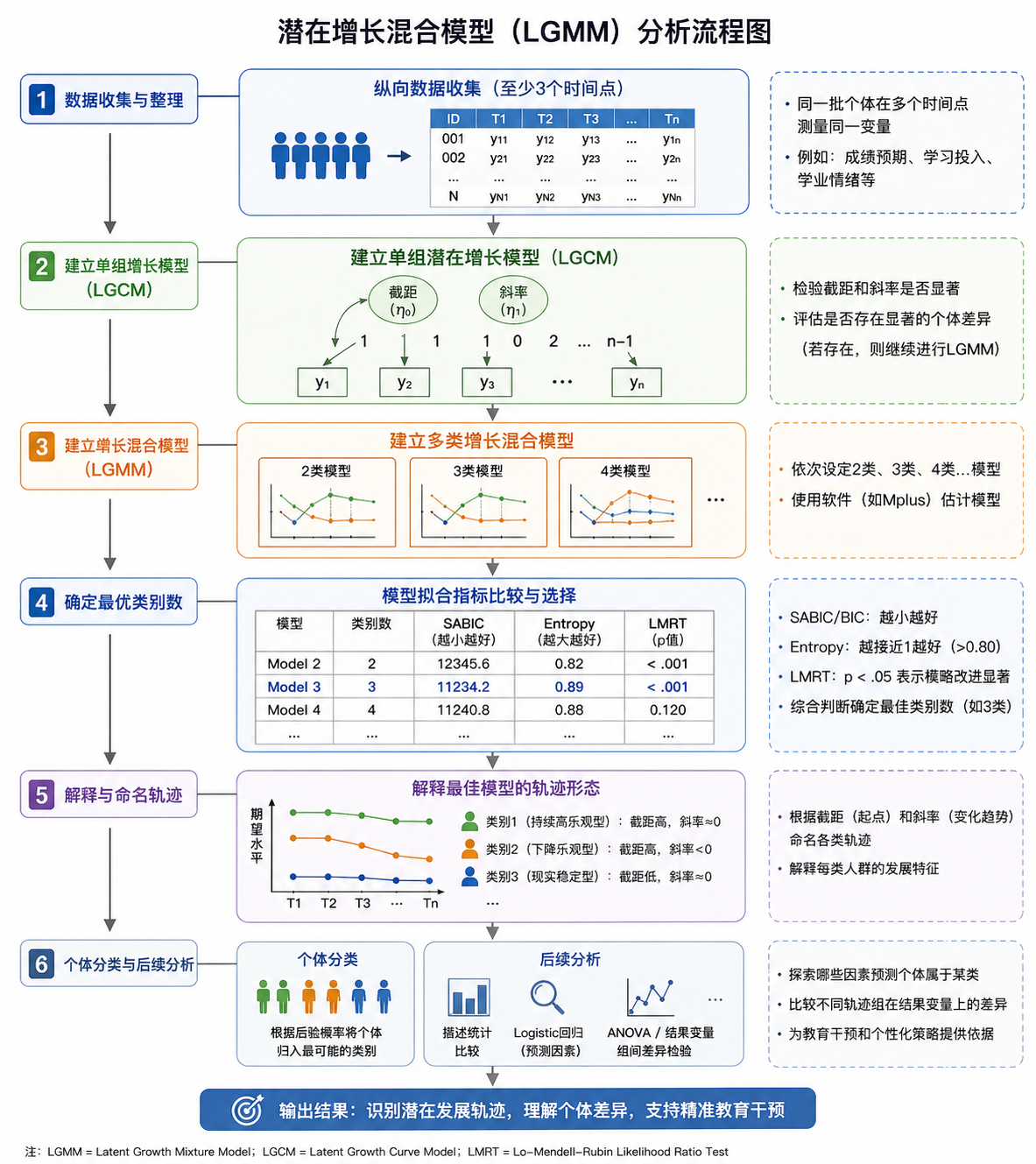
四: 方法的应用启示
🎯 适用情境
学习投入变化
学业情绪轨迹
成绩预期偏差
在线学习行为
辍学风险预警
学习动机变化
💡 教育实践启示
从“平均学生”转向“多类型学生”
教学更精准,而非“一刀切”
识别高风险群体
如“过度乐观但实际成绩差”的学生
支持个性化教学
不同轨迹 → 不同干预策略
❓ 值得进一步探讨的问题
LGMM能否与AI预测模型结合?
是否可以用于实时学习分析(learning analytics)?
不同文化背景下轨迹是否稳定?
轨迹是否会“转换”(latent transition)?
👉 LGMM让我们不再只看“平均变化”,而是看见不同学生如何以不同方式成长。
五:论文基本信息
Lee, J. Hannah, et al. “Trajectories of unrealistic optimism in grade expectation: A latent growth mixture model.” Social Psychology of Education 27.4 (2024): 1595-1620.
清华对LGMM在纵向数据中识别异质性轨迹的梳理很清晰。不过,一个关键前提是类别数量的确定依赖统计指标(BIC、Entropy等),但这些指标在不同样本量或模型设定下可能不稳定,甚至产生虚假类别。如果实际数据中轨迹是连续的而非离散的,强行分类是否会掩盖个体间的渐变差异?另外,你提到的应用场景如“过度乐观但实际成绩差”的学生,这里隐含了一个价值判断——乐观是否一定不好?如果乐观本身能带来积极行为(如更多努力),那么“不现实”的乐观是否也可能有适应性功能?这或许需要更谨慎的因果推断,而非直接将其归为高风险。
老师的疑问引发了我思考,也促使我对 LGMM 方法的应用与结果解释进行了更审慎的反思。首先,关于类别数量确定的问题,文献中在模型选择时,除了参考 BIC、熵值等统计指标外,也结合了轨迹可视化结果与理论意义进行综合判断,并报告了不同类别模型的拟合情况,以降低单一指标不稳定带来的偏差;同时,我也意识到 LGMM 本质上是用离散类别近似刻画连续变化轨迹,因此我发现文章在解读时,并未将类别视为互斥的 “固定群体”,而是将其理解为具有相似变化模式的亚群体,避免过度放大群体间差异、掩盖个体渐变特征。其次,对于 “不现实乐观” 与学业表现的关系,本研究的结论仅揭示了两者的相关轨迹模式,而非因果推断;我也认同 “不现实乐观” 可能具有适应性功能,如维持学习动机、驱动努力行为,我也发现文献在讨论中并未直接将其标签化为 “高风险”,而是强调其与学业结果的关联模式,为后续结合质性数据深入探讨这类学生的动机与行为机制留出了空间。这些质疑也启发我,在使用轨迹模型时,应更加注重方法的理论适配性、结果解释的审慎性,以及避免将统计分类等同于价值判断。
我觉得这个研究最吸引我的地方,是它把学生的发展差异从“平均数”里拎了出来。很多教育研究最后只会说某个群体整体上提高了、下降了,或者某种教学干预有没有显著效果,但这种说法其实很容易掩盖学生之间的真实差异。LGMM的价值就在于,它能看到不同学生可能走的是完全不同的发展轨迹:有的人一开始水平高但后劲不足,有的人起点低但慢慢追上来,还有的人可能一直处在比较稳定的状态。这个视角对教育实践很有意义,因为教师面对的从来不是一个抽象的“平均学生”,而是一群变化方式不同的真实学生。
感觉这个方法适合做学生的纵向长期追踪研究
这个帖子对LGMM的方法得拆解非常清晰,流程图尤其直观😍,让人一眼就能抓住从单组增长模型到混合模型的递进逻辑。帖子里提到的“从平均学生转向多类型学生”这一点特别有触动——传统的均值比较确实容易让人忽视群体内部的异质性。LGMM让数据“自己说话”去发现不同发展轨迹,这种数据驱动的分类思路比人为切分更有说服力👍。谢谢分享,学习了👻。
我对清华分享的这个方法很感兴趣!感觉通过动态异质性的数据进行分类,自动识别不同的发展轨迹,确实比分析一次横截面数据更适配教育场景,但虽然LGMM使用了大规模的动态数据,但我理解本质上这个模型的核心优势更多是解释性而非预测性的,因为它是对既有的数据进行分类,那么我在想,如果将来尝试把它用到真实的教育场景中,比如根据早期数据对学生进行分类或干预,会不会遇到一些需要谨慎处理的边界问题?比如标签效应或者误分类带来的影响?很想听听清华对这一点的看法。
中石😍😍的提问很能引发我的思考!!是的,我也了解到,LGMM 虽然能识别出不同的轨迹模式,但它本质上是描述性的相关分析,不能直接证明 “这种轨迹导致了差成绩”。而要判断轨迹和结果之间的因果关系,需要更严谨的研究设计,如纵向追踪和干预实验。如果直接用早期分类给学生贴标签,不仅模型的预测稳定性可能不足,还很容易带来标签效应和误分类风险。我觉得更稳妥的用法,是把它当成教师的 “辅助参考”,用来识别潜在的关注方向,再结合质性数据和教学判断做干预,这样既能发挥数据的优势,也能避免方法的局限性。
看完清华的分享,对我有一个启发,LGMM侧重去观察不同时间点参与对象的心理特征的变化,那么是不是可以将其和隐马尔科夫链,这种考察行为转移的方法结合起来,用于识别行为序列及心理状态随时间变化的潜在模式。
天娇师姐的想法非常有启发性!!我去了解了一下隐马尔可夫链这个方法,我发现,LGMM 和隐马尔可夫链的结合,刚好可以实现宏观 和微观的互补!比如说,LGMM 帮我们识别出不同学生群体的心理特征发展轨迹,划分出异质性亚群体;隐马尔可夫链则可以进一步分析,在每个轨迹类别内部,心理状态与行为序列之间的转移规律,分析出一些模式。这样一来,我们既能回答不同学生是怎么发展的,又能揭示发展过程中发生了什么,把轨迹分析从群体层面 推进到过程层面,非常适合深入研究!
很多教育研究最后都落到一个总体趋势上,只看到班级的平均水平,但真实课堂里学生差异太大了,有人是越学越踏实,有人可能一直高估自己。LGMM把这些隐藏轨迹分出来,对教学干预很有启发。不过我也觉得分类结果不能被过度标签化,学生不是固定类型,后续如果能结合轨迹转换来看,会更贴近真实成长过程。
这篇文献跳出了家庭教育研究中“重管教、轻情感”“单变量分析”的传统误区,创新性将工科领域的响应面分析与心理学、教育学研究结合,精准拆解了亲子关系与父母教育卷入的组合模式对青少年心理健康的复杂影响,堪称家庭教育量化研究的方法论范本。以往同类研究大多单独探讨亲子关系或教育投入的作用,即便涉及交互分析,也仅停留在简单交互项层面,无法直观呈现两者匹配失衡的差异化后果,而本文借助响应面分析构建三维模型,清晰揭示了“高关系-高卷入最优、双高优于双低、高关系低卷入远胜低关系高卷入”的核心结论,强有力佐证了情感联结优先于教育资源投入的核心观点,彻底打破了家长“只要狠抓学习就能养出好孩子”的认知误区。