
大家是否有没有遇到过这样的情况:论文里用了回归、PSM、IV,结果依然被审稿人质疑“遗漏变量”?你明明怀疑X对Y有因果效应,却总担心控制变量不够多、模型设定不对、非线性关系被忽略。今天这篇《双重机器学习在社会科学因果推断中的应用》,就是要告诉你一个好消息:我们可能终于找到了一把靠谱的“因果推断瑞士军刀”。
1. 方法的基本信息
核心思想
双重机器学习的本质是:用机器学习来“净化”因果推断中的混杂偏误。
传统回归做因果推断时最大的问题在于:我们不知道哪些变量是混淆变量,也不知道它们与X、Y的关系是线性还是非线性。DML通过两个核心步骤解决这个问题:
-
残差正交化:用机器学习模型分别预测Y和X,然后取残差,剥离掉混淆变量的影响。
-
交叉拟合:通过样本分割避免过拟合,保证估计量的无偏性。
-
独特价值
对比项 传统回归/OLS 倾向值匹配 工具变量 双重机器学习 控制大量混淆变量 ❌ 易多重共线性 ✅ 倾向值降维 ❌ 不适用 ✅ 可纳入上百个变量 处理非线性关系 ❌ 需要预设函数 ❌ 依赖倾向值模型 ❌ 需要线性一阶段 ✅ 自动捕捉非线性 因果异质性分析 ❌ 交互项有限 ❌ 难以实现 ❌ 难以实现 ✅ 灵活识别异质性来源 时间动态效应 ❌ 难以估计 ❌ 不适用 ❌ 不适用 ✅ 可估计动态因果效应 置信区间 ✅ 标准误易得 ✅ bootstrap ✅ 可计算 ✅ 可计算 -
关键产出
-
平均处理效应:X对Y的总体因果效应大小及显著性
-
条件处理效应:不同群体/情境下的因果效应异质性
-
动态因果效应:因果效应随时间的变化趋势
-
中介效应:间接效应与直接效应的分解
2. 方法的操作过程
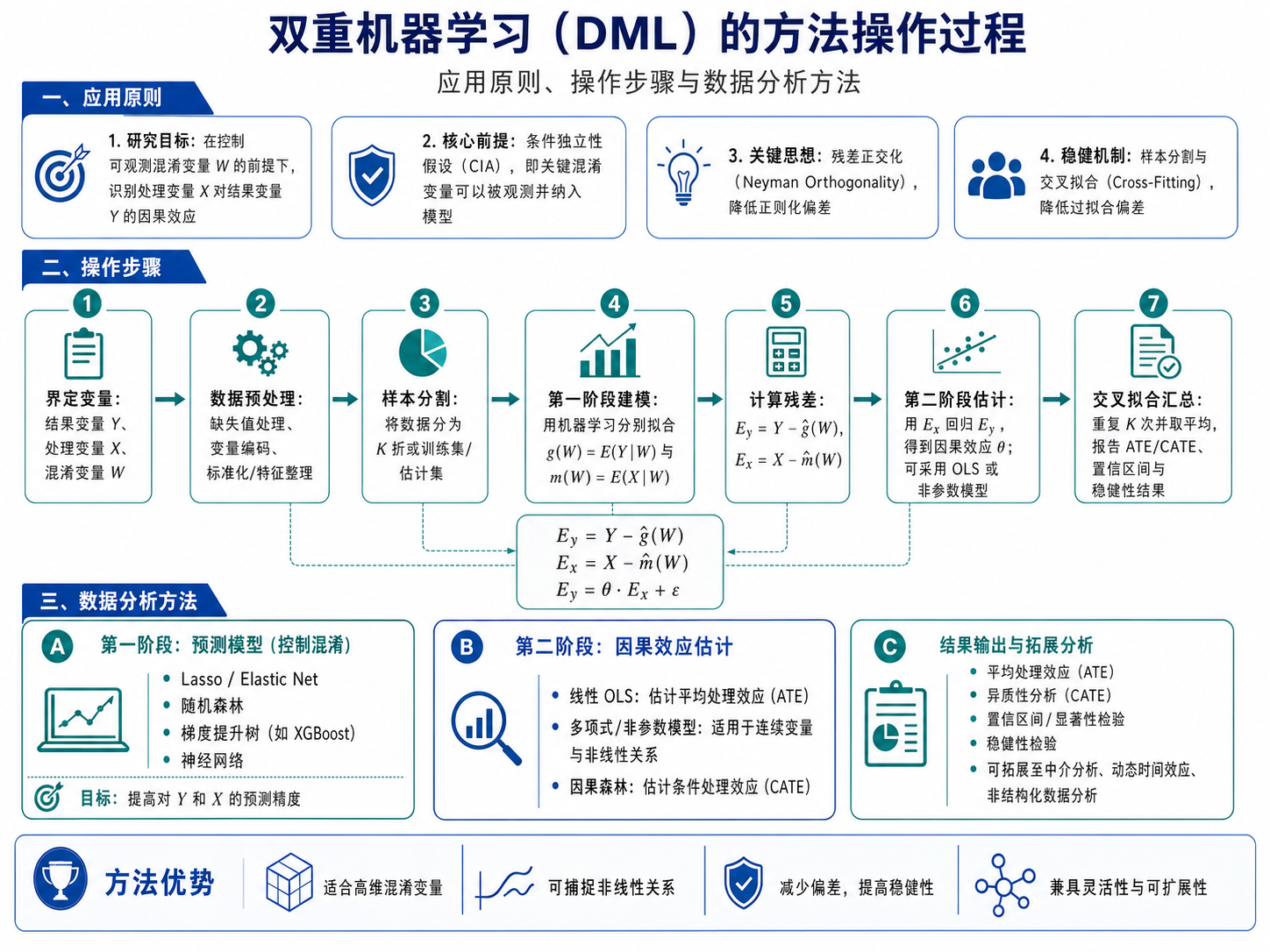
应用原则
DML的核心前提是:所有重要的混淆变量都必须可以被观测并纳入模型(条件独立假设)。换言之,它的优势在于“利用数据消除混淆”,而不是“绕过混淆”。
操作步骤
DML分三步走:
第1步:用混淆变量 W 预测 Y,得残差 E_y
-
-
Ey=Y−g^(W)
第2步:用相同的 W 预测 X,得残差 E_x
Ex=X−m^(W)
第3步:用 E_x 预测 E_y,得平均处理效应 θ
Ey=θ0Ex+ϵ
整个过程通过交叉拟合(K-Fold)重复K次,最终求平均,消除过拟合偏差。
-

-
数据分析方法搭配建议
研究目的 第一阶段的机器学习模型 第二阶段的因果模型 高维混淆变量 + 线性关系 Lasso / Elastic Net + 交叉拟合 OLS(得ATE+置信区间) 复杂非线性关系 随机森林 / XGBoost Lasso / 因果森林 因果异质性分析 随机森林 / XGBoost 因果森林 + SHAP解释 中介效应分解 任意ML模型(预测倾向值、中介变量、结果变量) 有效得分函数 + 交叉拟合 面板数据 + 动态效应 ML + 时序残差化 序贯g-估计 非结构化数据(文本/图像) 嵌入模型(Word2Vec/BERT) 嵌入向量 + DML DML的第一阶段只管“预测得准不准”,不需要可解释性;第二阶段只管“因果估计得对不对”,可以灵活选择参数或非参数模型。
-
3. 方法的应用启示
适用情境
研究场景 推荐使用DML的原因 控制变量非常多(几十甚至上百个) 传统回归面临多重共线性 & 过拟合风险,DML通过正则化+交叉拟合解决 X与Y的关系可能是非线性的 第一阶段ML自动捕捉非线性,避免模型设定偏误 想探索“因果效应在谁身上更强” 第二阶段用因果森林+SHAP,可自动识别关键调节变量 有面板数据,想看因果的时间变化 DML+时序残差化,可估计动态处理效应 想检验中介机制 DML+因果中介分析,具有多重鲁棒性,比传统方法更稳健 个人思考:DML不是万能钥匙
-
条件独立假设无法完全满足:如果关键混淆变量未被观测(例如“孩子天生能力”),DML再厉害也没用。此时更好的选择可能是面板数据、工具变量或断点回归。
-
机器学习预测不准 → DML结果不稳:DML的质量高度依赖第一阶段机器学习模型的预测精度。如果X或Y难预测,DML的估计也可能不理想。
-
可解释性问题:如果第二阶段用了因果森林等非参数模型,DML可以告诉你“谁被影响了”,但不容易告诉你“为什么是这些人”。
-
计算资源要求高:尤其是K-Fold + 复杂模型 + Bootstrap置信区间,数据量大时计算时间较长。
值得探讨的新问题
既然DML能在控制大量混淆变量的同时处理非线性关系,那么——
-
🤔 传统的“变量筛选”策略是否还有必要?是否应该把所有可能相关的变量都扔进DML?
-
🤔 DML是否可以与深度学习结合,直接处理图像、文本等非结构化数据中的混淆因素?
-
🤔 DML能否帮助我们做“反事实预测”,预测某个政策如果没实施会发生什么?
陈茁,陈云松.双重机器学习在社会科学因果推断中的应用[J].浙江社会科学,2025,(06):72-85+158.DOI:10.14167/j.zjss.2025.06.016.https://kns.cnki.net/kcms2/article/abstract?v=uxn9QsgV9c_LDJFebgWfyYmqRg8V_SwsQzEG6jmBfUMzY0eHv9washpcM4vvQnW98KEIVenwOJ5fso3-HxQA3YdcwTvAHk6kX7iGtry5jxWe91E7GsStAnHhxj2iU5F4GgQZa4JMvZlReiRulhezDpLgr1zbu-RvdMDE4IhpoZwskseRKdm4Ig==&uniplatform=NZKPT&language=CHS
-
玉伟对双重机器学习“用残差净化混杂”这一核心思路的提炼非常精准,尤其点出了它与传统方法在非线性处理上的本质差异。顺着这个思路,如果我们将条件独立假设从“可观测变量”扩展到“潜在混杂因子”,DML能否与隐变量模型或深度表征学习结合,在非结构化数据(如文本、图像)中自动提取并控制那些难以直接测量的混淆因素?这或许能进一步拓展其适用边界。
谢谢老师!您这个点提的很好。论文里DML处理文本、图像其实还比较“初级”——就是先转成向量,再拿去跑回归。这有点像先把东西翻译成数字,再去做净化。您说的“潜在混杂因子”,确实是比较麻烦。我的想法是:能不能让DML和那种能“自动提炼”深层特征的模型结合起来?让模型自己从原始数据里把那些看不见的混淆因素揪出来,然后再交给DML去“净化”。不过感觉也会有问题,比如说模型会不会为了猜得准,反而把不该用的信息也学进去了?这可能需要专门设计一种更加精确以及守规矩的学习算法。
机器学习正成为计量经济学的重要发展趋势。双重机器学习结合了机器学习的预测能力与传统计量经济学的因果框架,能够有效解决复杂混杂因素下的因果效应估计问题。例如,教育收益率是衡量教育经济价值的核心指标,但OLS和IV估计都会存在偏误,无法准确反映变量间的因果效应。IV方法能够有效识别出边际人群的教育回报,但本质上是局部平均处理效应(LATE),其结论仅适用于受政策影响的边际人群,不能直接推广到所有群体。有研究表明双重机器学习可放松线性假设,增强处理高维数据与非线性关系的稳健性。机器学习可从样本匹配和反事实预测两方面改进因果效应识别。
传统统计方法依赖于对变量关系和数据分布的严格假设,在处理复杂数据集时,常常显得力不从心。在处理高维数据时,随着变量数量的大幅增加,传统模型识别潜在混杂因素的难度更大,同时也会出现虚假相关的问题,使得真实的因果效应难以被准确估计。第一,机器学习不必先确定具体统计模型;其次,部分机器学习采用非参数统计方法。机器学习对变量关系和数据分布要求的放松有利于降低模型设定错误而导致的偏差,也可以使数据“自动”适配模型,提高因果推断的准确性。