
一、导语
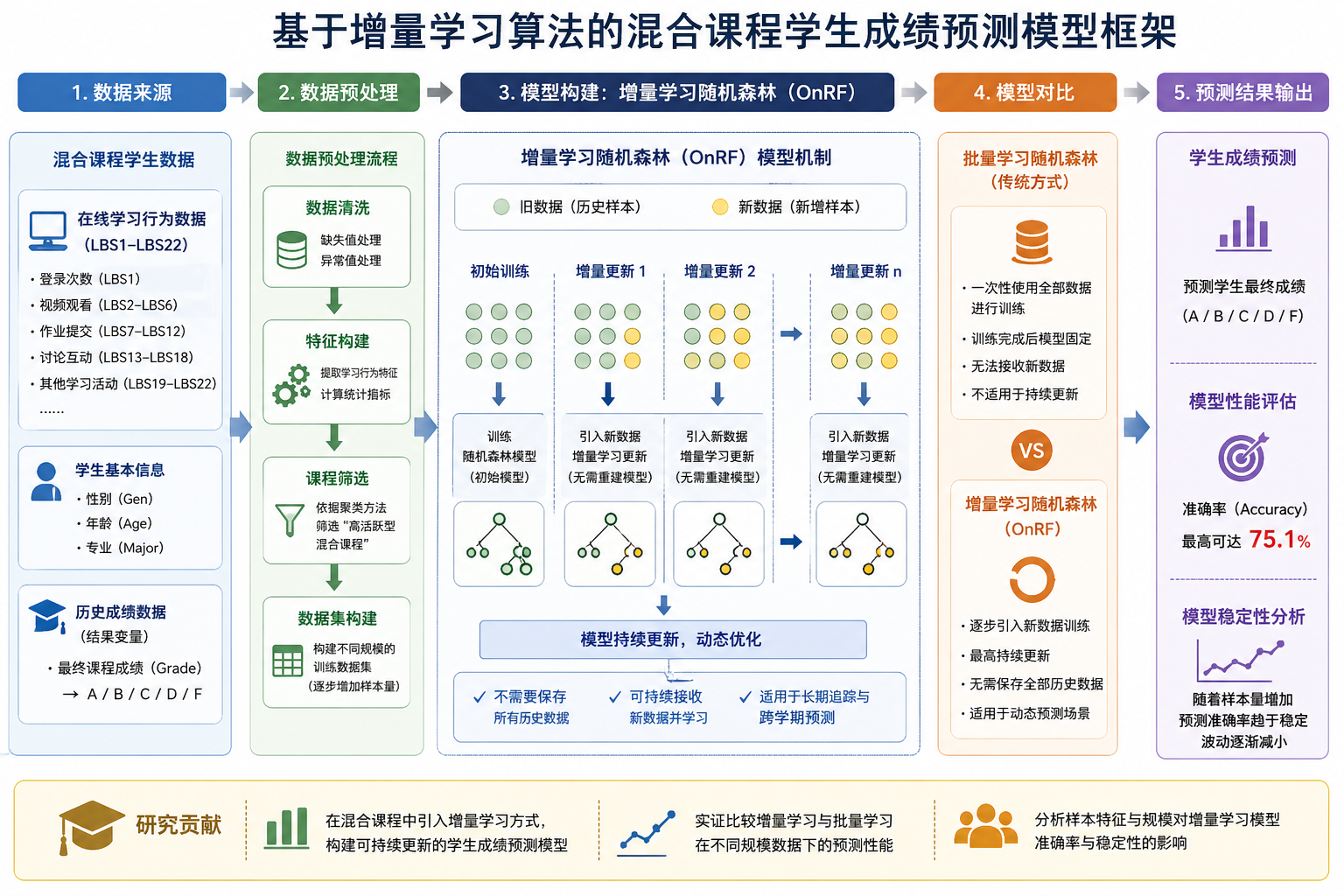
二、方法的基本信息
1. 核心思想
2. 独特价值
(3)适配教育场景:贴合混合课程 “数据持续产生、学情动态变化” 的真实教学逻辑。
3. 关键产出
(3)数据结论:验证了样本数量临界值规律,当课程样本量达到 41 门以上时,增量模型预测效果趋于稳定;
(4)方法产出:形成针对教育偏态行为数据的预处理、校正、降维、建模一体化量化操作体系。
三、方法的操作过程
1. 应用原则
(2)数据客观性原则
全程依托智慧教学平台后台原始行为数据,无主观打分、人为赋值,保证量化数据真实客观。
(3)双组对照原则
全程采用批量随机森林模型 VS 增量随机森林模型平行对照,控制变量一致,客观对比两种算法的优劣。
(4)适度校正原则
教育学习行为数据普遍存在偏态、极值、离散问题,遵循弱干预校正原则,仅做标准化与分布修正,不篡改原始数据特征。
(5)分层评估原则
不单一使用准确率指标,结合分类研究常用的查全率、F1 值、离散程度等多维指标,综合评判模型性能。
2. 完整操作步骤
步骤 1:研究样本与原始数据采集
从智慧教学平台后台抓取20 项原始在线学习行为指标,包含:课程登录频次、资源浏览时长、视频观看完成度、章节测验作答情况、课堂互动次数、作业提交质量、论坛讨论行为等;
因变量为学生期末课程成绩,按照高校考核标准划分为 5 个等级,构建多分类预测研究框架。
步骤 2:原始数据清洗与基础预处理
步骤 3:数据分布校正与特征优化
针对性开展双重数据变换处理:采用对数变换、指数变换方式修正数据分布,弱化极值干扰,使行为数据趋近于正态分布,提升模型拟合效果。
步骤 4:课程类型聚类筛选
最终筛选高活跃混合课程作为核心研究样本,保证变量差异显著、研究结论具有代表性。
步骤 5:对照组与实验组模型搭建
② 实验组:增量在线随机森林模型(OnRF),按照课程时序顺序逐批录入样本,模型逐次迭代更新,不重置整体结构、不重复全量训练。
步骤 6:模型超参数调试与训练约束
采用交叉验证方式规避过拟合、欠拟合问题,保证对照实验的公平性与科学性。
步骤 7:模型输出与结果统计
3. 核心数据分析方法
(1)描述性统计分析
(2)数据分布修正分析法
- 对数变换:压缩高值区间数据,降低极端学习行为样本的权重干扰;
- 指数变换:优化低值数据区分度,弥补低频学习行为指标辨识度不足的问题;
通过变换前后分布对比检验,确认数据优化效果,满足机器学习算法的数据输入要求。
(3)K-Means 聚类分析
以学生整体学习行为的聚合特征为聚类依据,自动划分课程活跃度类型,量化区分高活跃课程与低互动课程,解决人为分类的主观性偏差,实现研究样本客观筛选。
(4)随机森林集成学习算法(批量版)
① 采用自助采样法抽取样本子集、特征子集,降低单一决策树过拟合风险;
② 以基尼系数作为节点分裂依据,挖掘各学习行为指标与成绩的非线性影响关系;
③ 整合多棵决策树投票结果,输出多分类预测结果,作为基准对照模型。
(5)增量在线随机森林算法(核心创新分析方法)
① 增量迭代机制:模型无需加载全量历史数据,新增课程样本可逐条、逐批输入;
② 动态树结构更新:保留原有成熟决策树框架,仅新增分支、微调节点权重,大幅降低运算量;
③ 时序数据适配:适配教学数据逐年、逐学期新增的时序特征,实现模型长期可持续更新。
(6)多分类模型效能检验
- 准确率:整体预测正确样本占比,反映模型整体精准度;
- 精确率:各成绩等级下预测结果的可信程度;
- 查全率:真实等级样本被成功识别的覆盖能力;
- F1 综合值:平衡精确率与查全率,客观反映综合分类性能;
- 标准差分析:计算多批次实验结果的离散程度,量化评判模型稳定性,是本研究重点新增的量化分析维度。
(7)阈值对比分析
4. 方法逻辑流程图

四、方法的应用启示
1. 适用情境
可落地于高校日常教学管理,依托增量模型实时更新学生学习状态数据,实现阶段性学业风险预判,辅助教师开展分层教学、个性化干预。
(3)教育测评与质量评估场景
用于分析学习行为、学习投入、线上互动等隐性变量与学习结果的关联,丰富过程性评价的量化工具。
(4)跨周期追踪研究场景
适合跨学期、跨学年的追踪式量化调研,解决传统模型无法持续更新、重复建模成本高的现实难题。
2. 个人思考
第三,从实践层面来讲,增量模型低成本、可迭代的优势,非常契合中小学、高校智慧校园建设需求,能够实现一套模型长期复用,兼具科研价值与实践落地价值。
第四,从研究设计来看,双模型对照、多指标检验的研究设计,极大提升了结论的可信度,这种严谨的对照研究范式,值得所有教育量化研究借鉴。
晓霄对增量学习随机森林在混合课程成绩预测中的应用梳理得非常清晰,尤其是双模型对照和多指标检验的设计,确实提升了结论的可信度。顺着这个思路,如果将该模型迁移到中小学线上线下融合场景,考虑到中小学生行为数据更稀疏、课程周期更短,增量学习的临界样本阈值是否需要重新界定?此外,多模态数据的引入会显著增加特征维度,增量随机森林的树结构更新机制能否有效应对高维动态特征?这或许是一个值得深入探讨的方向。
感谢老师的细致点评与提问!!
首先,把增量随机森林迁移到中小学线上线下融合场景,由于中小学生学习行为数据更稀疏、课程周期更短、行为维度更少,我认为原论文得出的41 门课程临界样本阈值不能直接套用,可能需要重新做梯度样本实验、重新界定适配中小学场景的模型稳定阈值。
第二,未来引入眼动、表情、课堂语音等多模态数据后,特征维度会显著增加,我觉得增量随机森林自带的动态树结构更新机制,理论上具备应对高维动态特征的潜力,但存在高维特征冗余,后续可以做特征精简,再搭配增量森林的迭代更新机制,去适配多模态高维时序数据。
这篇聚焦清华团队增量学习随机森林(OnRF)模型的研究解析,紧扣当下混合式教学普及、教育大数据爆发的现实背景,直击传统批量学习模型“无法动态迭代、预测稳定性差、重复训练成本高”的行业痛点,提出的解决方案兼具学术创新性与实践落地性,是教育技术与机器学习融合研究的优质范例。高校混合课程学情数据具备时序性、持续性、高维度的特点,传统机器学习模型需要整合全量数据重新训练,无法适配跨学期、跨课程的动态监测需求,而本文介绍的OnRF模型依托增量学习机制,无需重复全局训练,可直接纳入新数据更新参数,大样本下预测准确率与稳定性大幅提升,还明确了41门课程的样本稳定临界值,为实际教学应用提供了量化参考标准。