
1. 导语 🌟 AI 越来越聪明,但它怎么知道我们“真正想要什么”?
以前的AI总是喜欢“一本正经地胡说八道”,但现在的AI却像个贴心助手。这中间的秘密武器到底是什么?今天给大家分享一篇彻底改变大语言模型进化轨迹的里程碑式论文。一起来看看,研究者是如何通过一种创新的量化方法——RLHF(基于人类反馈的强化学习),像教导小孩子一样,把人类的价值观和偏好“注入”到冷冰冰的算法中的!一起来解锁当前最火爆的AI 核心训练黑科技吧!🔥
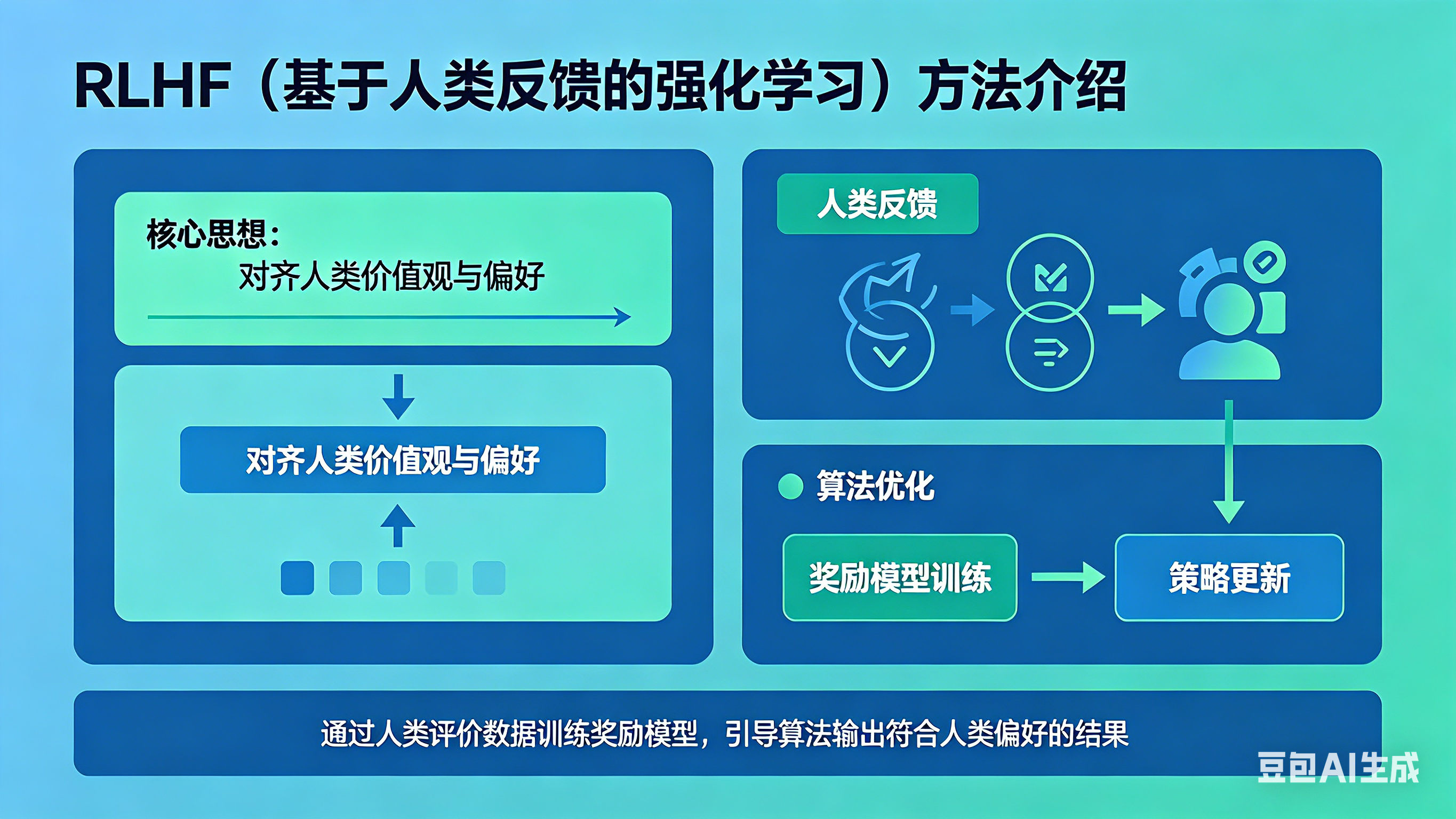
2. 方法的基本信息
– 核心思想: 传统的语言模型只知道“预测下一个词”,而 RLHF(Reinforcement Learning from Human Feedback)
方法的核心思想是**“对齐(Alignment)”**。它通过引入人类的真实偏好数据,结合强化学习算法,引导模型生成有用(Helpful)、诚实(Honest)、无害(Harmless)的内容。
– 独特价值:
突破了单纯依靠海量数据进行无监督学习的瓶颈。它证明了:不需要无脑增加模型参数,只需用少量高质量的“人类偏好反馈”作为奖励信号,就能让AI的表现产生质的飞跃。这种方法成功搭建了纯概率统计模型与人类复杂主观价值观之间的桥梁。
– 关键产出: 训练出一个能精准模拟人类喜好的奖励模型(Reward Model),并产出一个高度听从人类指令的策略模型(Policy Model,即最终的大模型)。
3. 方法的操作过程 (注:此部分配合下方建议的配图食用最佳)
– 应用原则: 监督学习打底,人类偏好排序,强化学习升华。
– 操作步骤(经典的“三步走”战略):
1. SFT(监督微调): 收集一部分高质量的人工编写问答数据,对预训练模型进行初步微调,让它学会“如何回答问题”。
2. RM(训练奖励模型):
让第一步的模型对同一个问题生成多个不同回答,人工(标注员)对这些回答的质量进行排序。利用这些排序数据训练一个打分器(奖励模型),让它学会像人一样给AI的回答打分。
3. RL(强化学习优化): 利用 PPO(近端策略优化)算法。让模型不断生成回答,RM
给回答打分,模型根据分数高低不断调整自身参数,最终达到奖励最大化。
– 数据分析方法等: 使用了 Bradley-Terry 模型将人类的“排序偏好”转化为量化的“损失函数”;使用 PPO(Proximal Policy Optimization)强化学习算法进行策略梯度的迭代与更新。
4. 方法的应用启示
– 方法的适用情境:
该方法不仅适用于自然语言处理,还可以广泛应用于图像生成、推荐系统、自动驾驶,甚至教育领域的开放性主观题自动评分等任何需要与“人类主观偏好”对齐的场景。
– 个人思考:
这种方法的巧妙之处在于“授人以渔”。与其费力气手写规则告诉AI什么不能说,不如教AI一个“裁判(RM)”,让AI在不断的试错和被打分中自我进化。这其实和人类社会中的教育与社会化过程非常相似。
– 值得探讨的新问题(欢迎大家讨论!):
1. 谁来代表“人类的偏好”?如果标注员本身存在偏见,AI是不是也会变成偏见放大器?
2. 这种方法极其依赖昂贵的人工标注,未来能否用AI来替代人类给AI打分(即 RLAIF)?
3. 如果把这个方法引入教育学,我们能否训练一个完全契合某位名师评分标准的“专属作文批改模型”?
5. 论文基本信息
– 文章引用信息 (APA格式): Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.
L., Mishkin, P., … & Lowe, R. (2022). Training language models to follow
instructions with human feedback. Advances in Neural Information Processing
Systems (NeurIPS), 35, 27730-27744.
沐村对RLHF中Bradley-Terry模型将人类排序偏好量化为损失函数的思路把握得很准。不过顺着这个方向,如果奖励模型本身存在标注偏差,PPO优化是否会放大这种偏差,甚至导致模型在看似高分但实际有害的路径上越走越远?你提到教育场景的作文批改,但学生的创造性表达往往难以用单一偏好排序来量化,这种情况下RLHF的适用边界该如何界定?
感谢老师的精准点评与深刻提问!关于奖励模型标注偏差是否会被PPO放大,答案是有可能但可控,行业会通过优化标注流程、在PPO阶段加约束机制来修正偏差;而教育场景中RLHF的适用边界,应是分场景分层适用,其适合作文基础维度评分,创造性表达需结合教师主观判断,避免扼杀创造力。你的问题指向RLHF“量化人类偏好”与“保留人类价值复杂性”的核心矛盾,期待进一步探讨。
这篇文章说明AI体验不只由参数规模决定,生成答案是否对齐人类需求同样关键。AI大模型可以“说很多”,但会答非所问。所以这篇论文把问题从“提升语言建模能力”转成了“对齐用户需求”的问题,说明如何将隐形的人类偏好转化为显式数据指标并加以优化。面对人类多样性、带有个人思维特色的语言指令,AI模型无法完全理解,不知道人类想要什么。但通过“三步走”战略训练语言模型,这样AI模型学会了遵循指令,更能满足人类语用需求,明白人类想要什么。但人类的需求、价值、喜好等有多种类型,未来可训练多偏好条件化奖励模型,或者使模型能够接入文献数据库,构建可根据不同文化背景、不同研究领域的用户群体偏好调整的训练奖励模型。
这篇关于RLHF的分享选题很有前沿性,把大模型最核心的对齐技术讲得非常透彻。作者没有停留在技术表面,而是抓住了“从预测单词到对齐人类偏好”这一范式革命,清晰拆解了SFT-RM-RL三步流程,既专业又易懂。文章最大的亮点是把技术原理和教育隐喻结合,用教孩子来类比RLHF,让人理解其价值,同时提出的标注偏见、成本、教育评分适配等问题,直击理论与应用痛点。
谢同学的这篇文章介绍了PLHF,这种基于人类的反馈学习能够让大模型像个贴心助手,这里面训练需要大量的人类价值观及其偏好的数据,我之前对AI对青少年精神品格的培养与干预感兴趣,当时就有一个担心与困惑,我看谢同学在“值得探讨的新问题”中也提及了,就是如果文本材料本身就带有偏好,这个方法能不能有效识别,是进一步放大还是缩小。并且这里面还有人类的价值观,这种人类的价值观是普世价值观,还是会受到人种、国别、民族等因素的影响,我觉得这是一个很重要的问题,因为这个技术会让AI变得越来越具有真人感,那么就必须要警惕这个互动中对于价值观的塑造与改造,警惕价值渗透😁