
导语:
如何应用前沿的统计技术对超过 41 万名青少年学生的海量数据进行深度挖掘?机器学习可以轻松完成~
在校园欺凌的量化研究中,基于大样本的机器学习有利于是从众多相关因素中发现关键因素的有效手段,也根据因素重要性排序。传统计量经济学研究通常纳入几百—几千个样本和少数关键变量,可能面对其复杂成因时显得力不从心。一方面,传统线性回归等经典统计模型难以捕捉风险因素与校园欺凌受害者之间的复杂非线性关系,且无法有效排序因素重要性;另一方面,针对网络欺凌的现有研究多聚焦于个体的网络行为与社交语言等,忽视了个体与家庭、学校、同伴等内外部因素的交互作用,导致统计模型的实用性与精准度不足。
以往研究表明大多数青少年学生网络受害者也是传统的校园欺凌受害者,网络欺凌者也是传统的校园欺凌者,在互联网时代,网络欺凌与传统欺凌的叠加风险不断增加。因此本研究通过机器学习分析大量数据集,构建能区分两类欺凌受害高 / 低风险青少年的模型,为校园欺凌的防治提供理论与现实依据。
(一)研究背景

(二)传统研究方法的局限性
1. 线性关系假设
传统方法(如多元回归)通常假设风险因素与欺凌结果之间存在线性关系,这可能过度简化了现实世界中复杂的相互作用。
2. 无法对变量进行重要性排序
传统统计方法难以对众多潜在风险因素的预测能力进行量化和排序,无法明确指出哪些因素是最重要的。
3. 预测精度有限
由于上述局限性,传统统计方法的预测准确性可能受限,难以满足精准识别高危个体的需求。
(三)机器学习的优势

二、研究设计
(一)数据来源
研究样本包括来自中国29个省份和138个城市中的435个学校的学生,涵盖小学、初中和高中,共计414,188名学生(女生48.8%,n=202,028;男生51.2%,n=212,160)。

(二)问卷设计
1. 欺凌受害评估
通过 3 个问题分别测量传统欺凌受害与网络欺凌受害,采用 6 点计分
(1) 传统欺凌受害
“近几个月,其他孩子故意伤害或捉弄你的频率?”
(2)网络欺凌受害
“近几个月,其他孩子通过社交媒体给你发送不受欢迎信息的频率?”
“近几个月,其他孩子在网站上发布关于你的负面内容的频率?”
2. 个体因素
(1)人口学特征
性别、年龄、兄弟姐妹数、出生顺序、年级
(2)生活行为
每周运动天数、每日屏幕 / 游戏 / 视频 / 阅读时间、每月线上课外班频率
(3)健康状况
BMI、抑郁症状、积极体验指数、消极体验指数、生活满意度、积极心理健康、躯体疾病、住院史、近视程度、睡眠时间、饮酒史、吸烟史、二手烟暴露
3. 家庭因素
亲子沟通频率、主要照料者、家庭社会经济地位
4. 学校因素
学校区域、学校类型
5. 同伴因素
主观同伴地位、学校好友数量
(三)研究方法
1. 统计模型:六种常用机器学习算法
(1)逻辑回归(Logistic Regression)
(2)朴素贝叶斯(Naive Bayes)
(3)决策树(Decision Tree)
(4)随机森林(Random Forest)
(5)K 近邻(K-Nearest Neighbors, KNN)
(6)轻量级梯度提升机(LightGBM)
2. 统计软件: Python
三、研究结果
(一)模型性能评估指标
准确率、精确率、特异度、召回率和F1分数
(二)性能最佳的算法
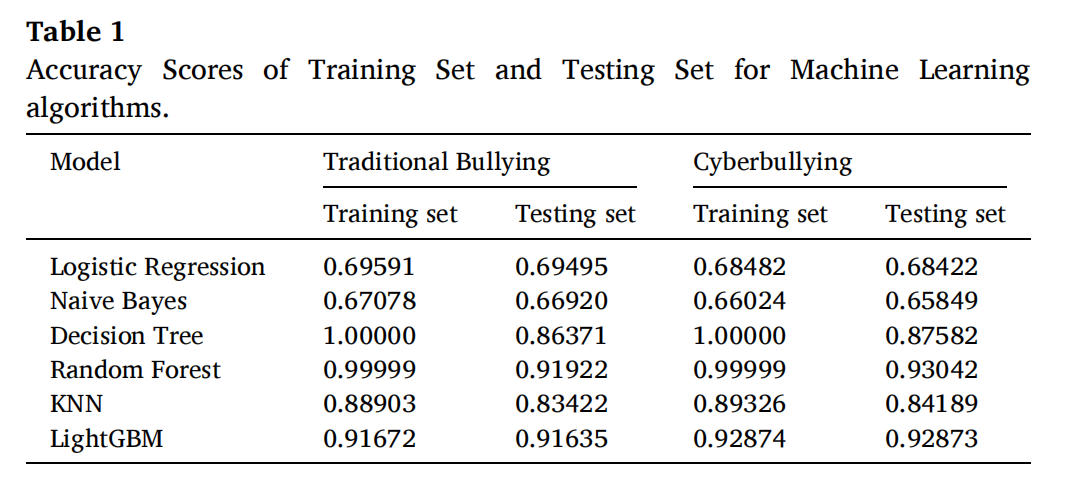
表1
表1显示了传统欺凌和网络欺凌的机器学习算法的训练准确率和测试准确率。总体而言,随机森林算法轻量级梯度提升机算法都提供了大于0.90的良好测试准确率,能够正确分类所有特征以准确预测欺凌受害情况。
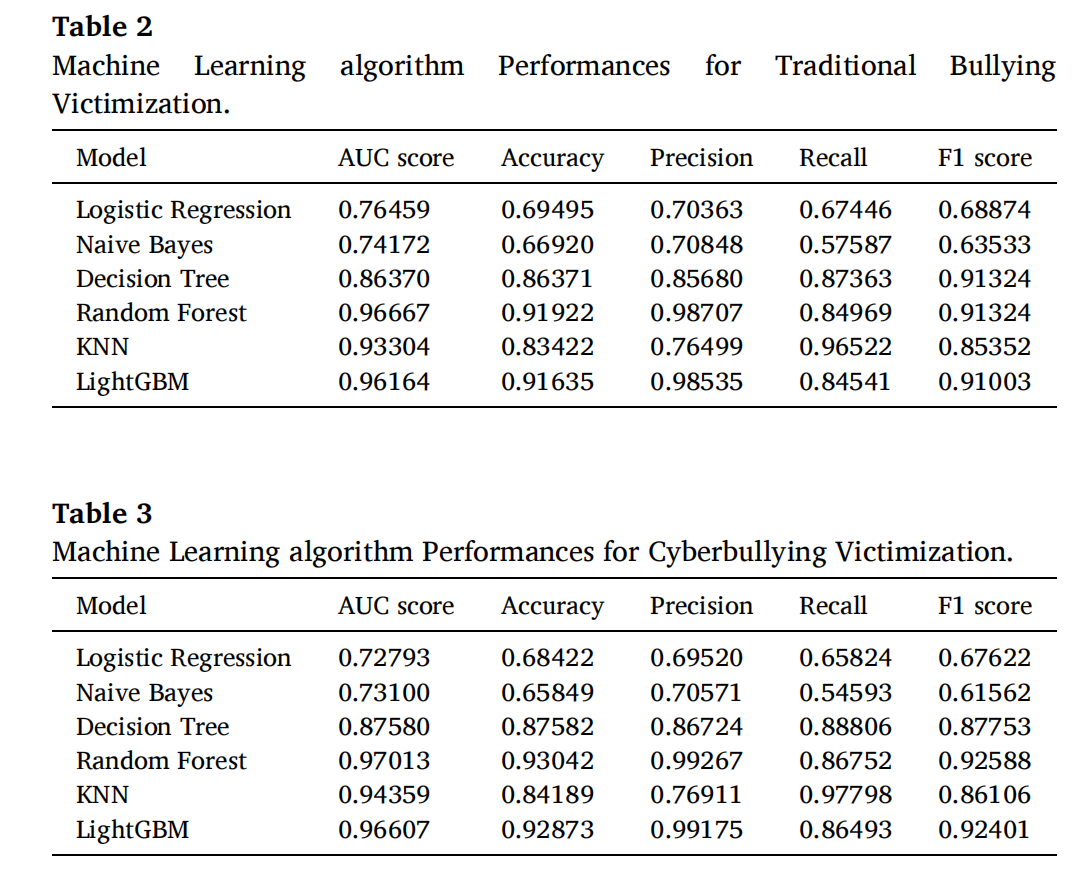
表2和表3
逻辑回归、决策树、K近邻和朴素贝叶斯算法各项指标得分较低。
随机森林算法和轻量级梯度提升机算法的准确率、精确率、召回率和F1得分显著优于其他算法。其中,随机森林算法在传统欺凌受害和网络欺凌受害的精确率上得分最高(分别为0.98707和0.99267)。其次,轻量级梯度提升机算法在传统欺凌受害和网络欺凌受害的精确率上也表现相对较好(分别为0.98535和0.99175)。此外,随机森林算法轻量级梯度提升机算法的准确率得分大于0.90,F1得分高于0.90,表明这两种算法相对更适合探测传统欺凌受害和网络欺凌受害的风险因素。
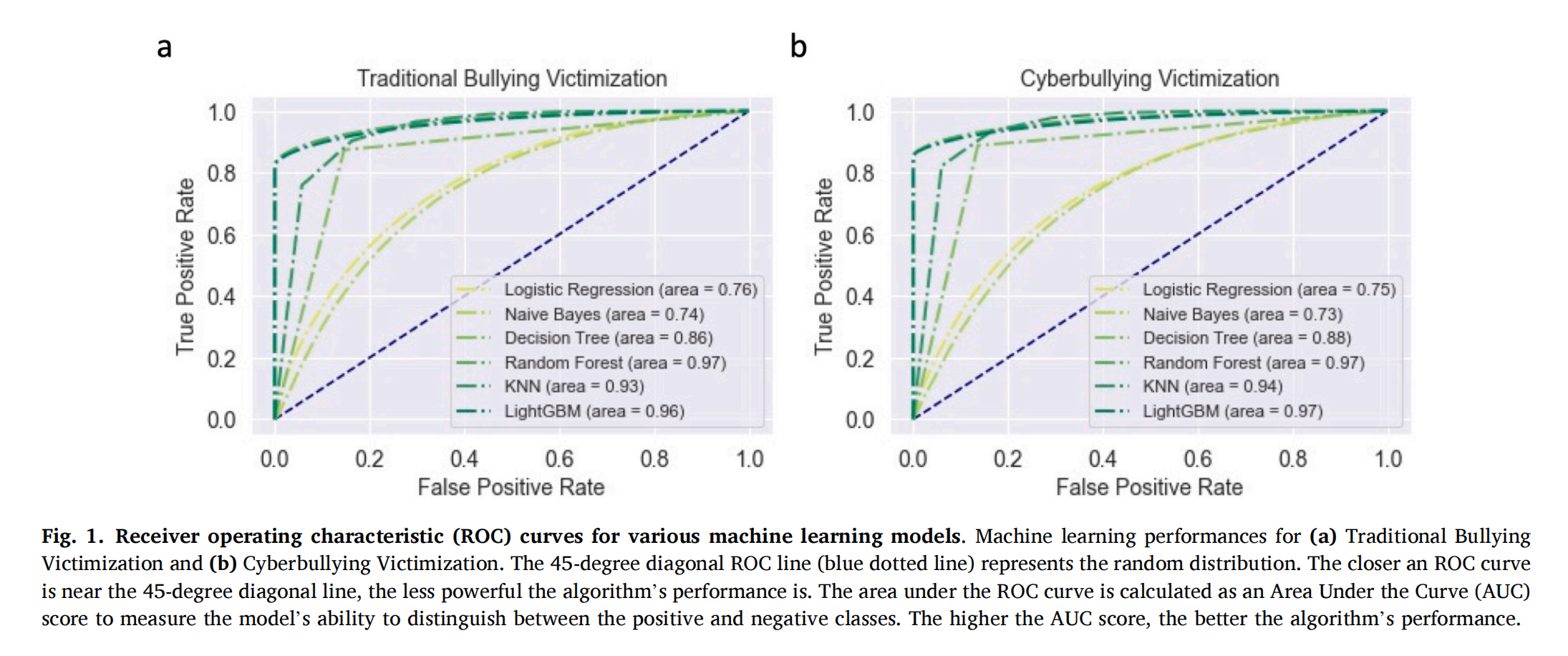
图1
ROC曲线结果显示,随机森林与Light GBM算法的曲线远离 45° 随机线,AUC 值分别达 0.97(传统欺凌受害)、0.97(网络欺凌受害)和 0.96(传统欺凌受害)、0.97(网络欺凌受害),表明这两种算法对受害与非受害样本的区分能力显著优于其他算法。
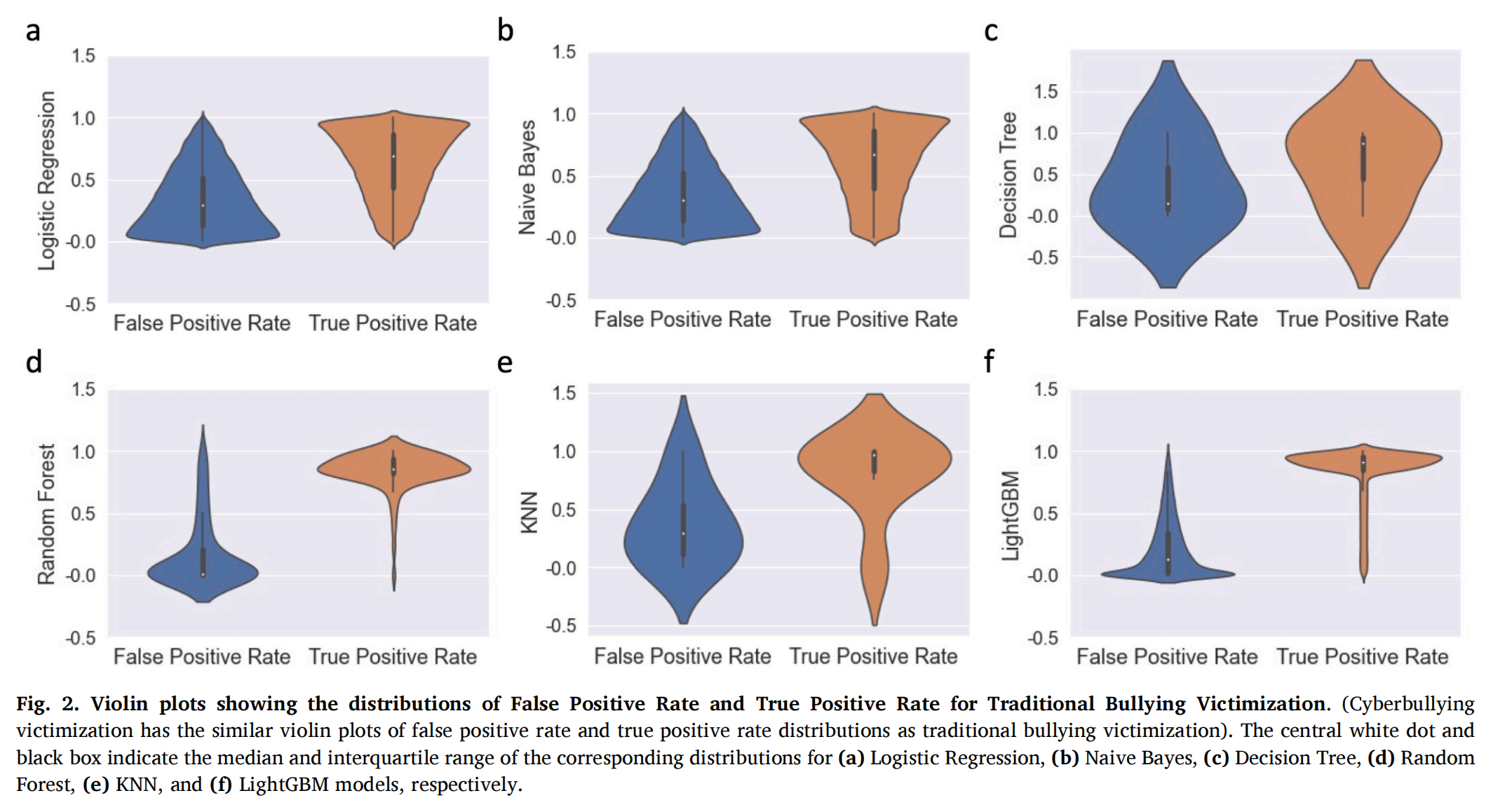
图2
小提琴图可视化假阳性率与真阳性率分布,进一步验证了随机森林与轻量级梯度提升机算法的优势性能。这两个算法模型假阳性率中位数接近0(极少误判非受害样本),真阳性率中位数接近1(能有效识别受害样本),两者分布差异显著,分类边界清晰。
(三)特征重要性分析:识别关键风险因素
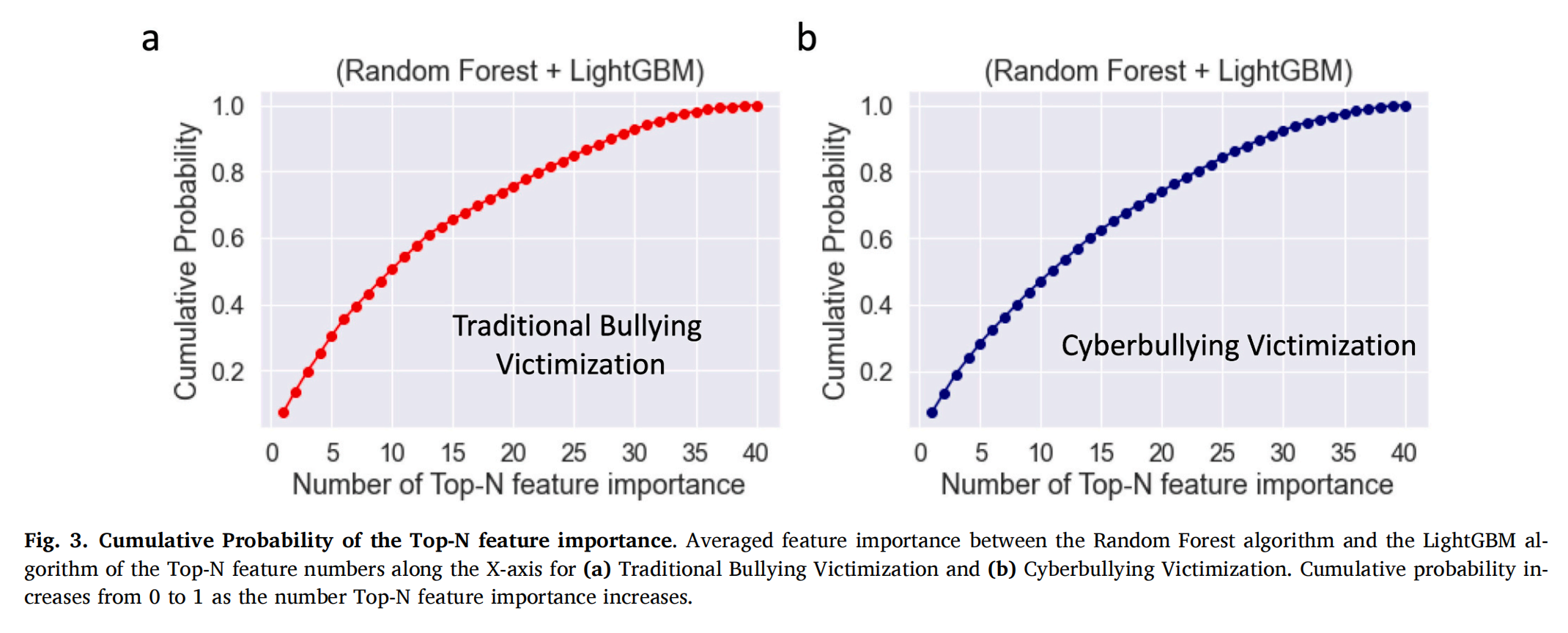
图3
通过特征重要性累积概率曲线分析发现,当纳入前 25 个特征时,综合模型对传统欺凌受害与网络欺凌受害的预测准确率均达 80%,表明这 25 个特征是欺凌受害的核心影响因素。
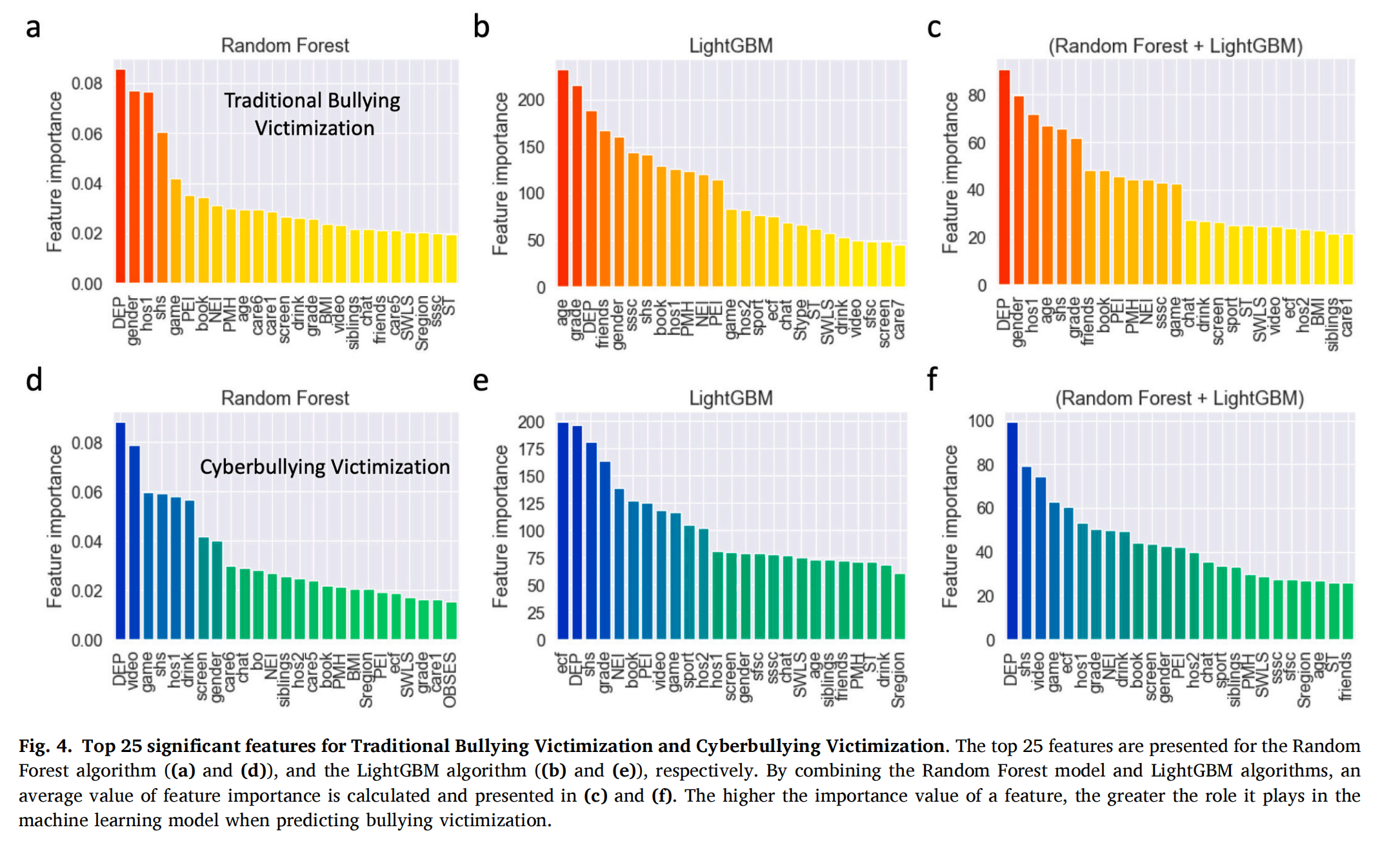
图4
图4中c和f表明,“抑郁”是传统欺凌受害和网络欺凌受害的最相关特征。此外,青少年的“性别”“身体健康状况”“年龄”“二手烟环境”“年级水平”和“良好朋友数量”等特征对传统欺凌受害起到关键作用。其中,“二手烟环境”“观看视频时间”“游戏时间”“在线课外课程参与”“身体健康状况”和“年级”的特征对网络欺凌受害有显著贡献。
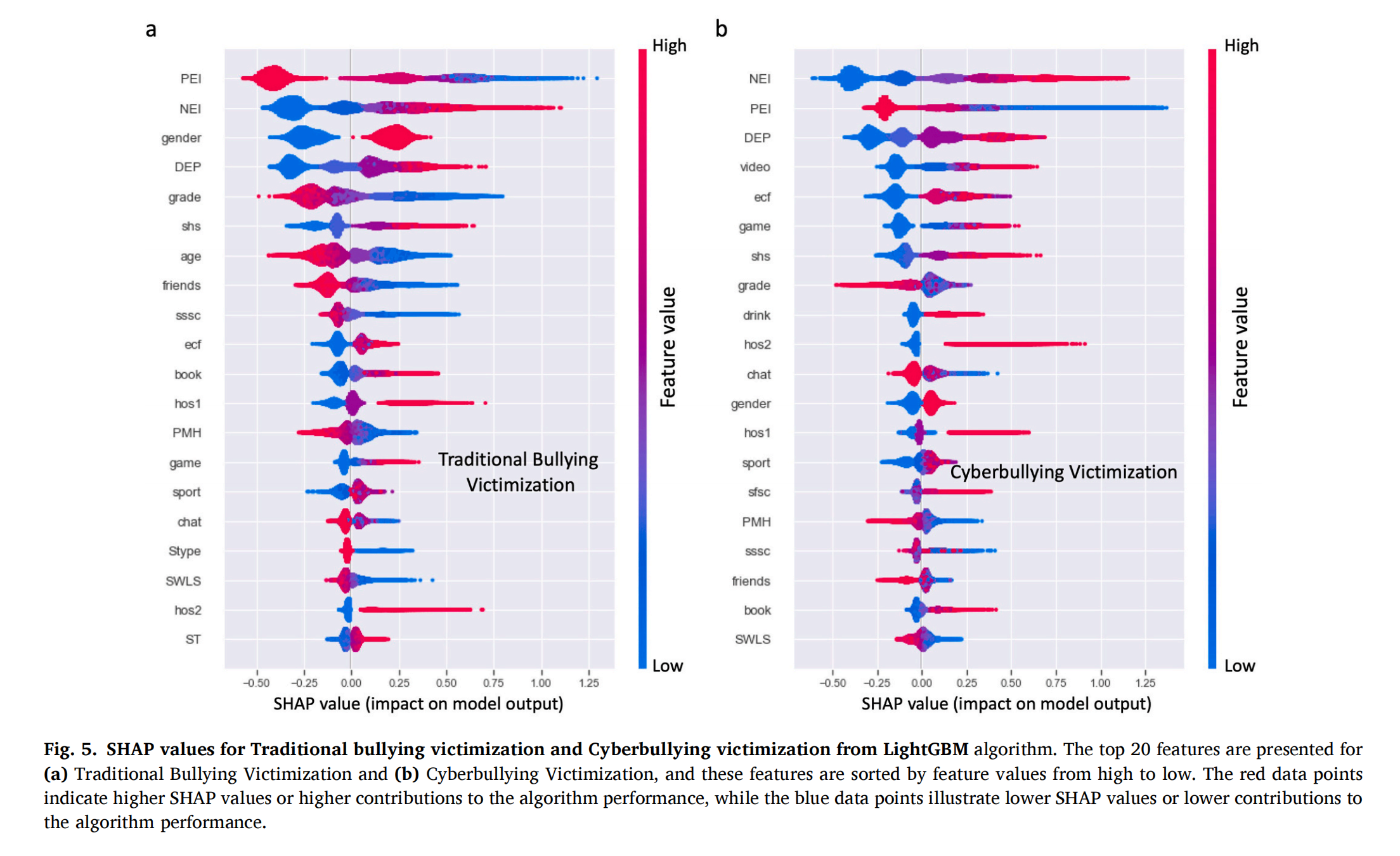
图5 SHAP蜂群图
图5量化了变量影响方向和强度。当特征值增加时,点的颜色越红;当特征值减少时,点的颜色越蓝。其中,积极经历(PEI)是最强的保护因素之一,对降低传统 / 网络欺凌风险的贡献都非常显著;消极经历(NEI)是最强的风险因素之一,对升高传统 / 网络欺凌风险的贡献都非常显著。
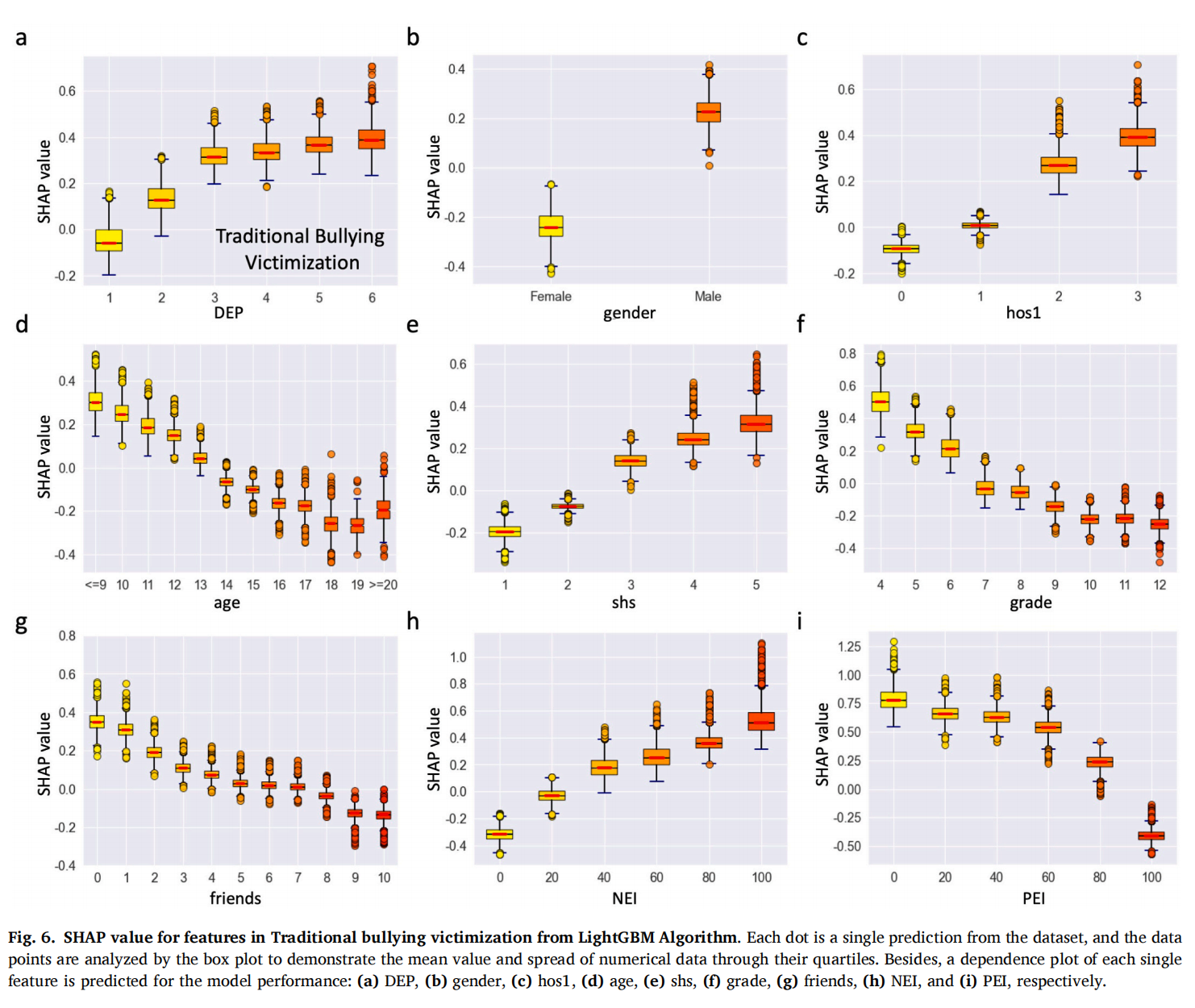
图6
图 6 和图 7 进一步说明了这些最重要因素对欺凌受害影响的方向。当SHAP值大于0时,模型预测样本学生已受到欺凌。
在图 6 中,抑郁程度更高(DEP≥2)、性别为男性、就医和服药频率较高(hos1≥2)、年龄较小(age≤13 岁)、接触二手烟频率高(shs≥3)、处于小学阶段(grade≤6 )、学校好朋友数量较少(friends≤7 )、消极经历指数较高(NEI≥40)且积极经历指数较低(PEI≤80),是识别学生传统欺凌受害更重要的9个风险因素。
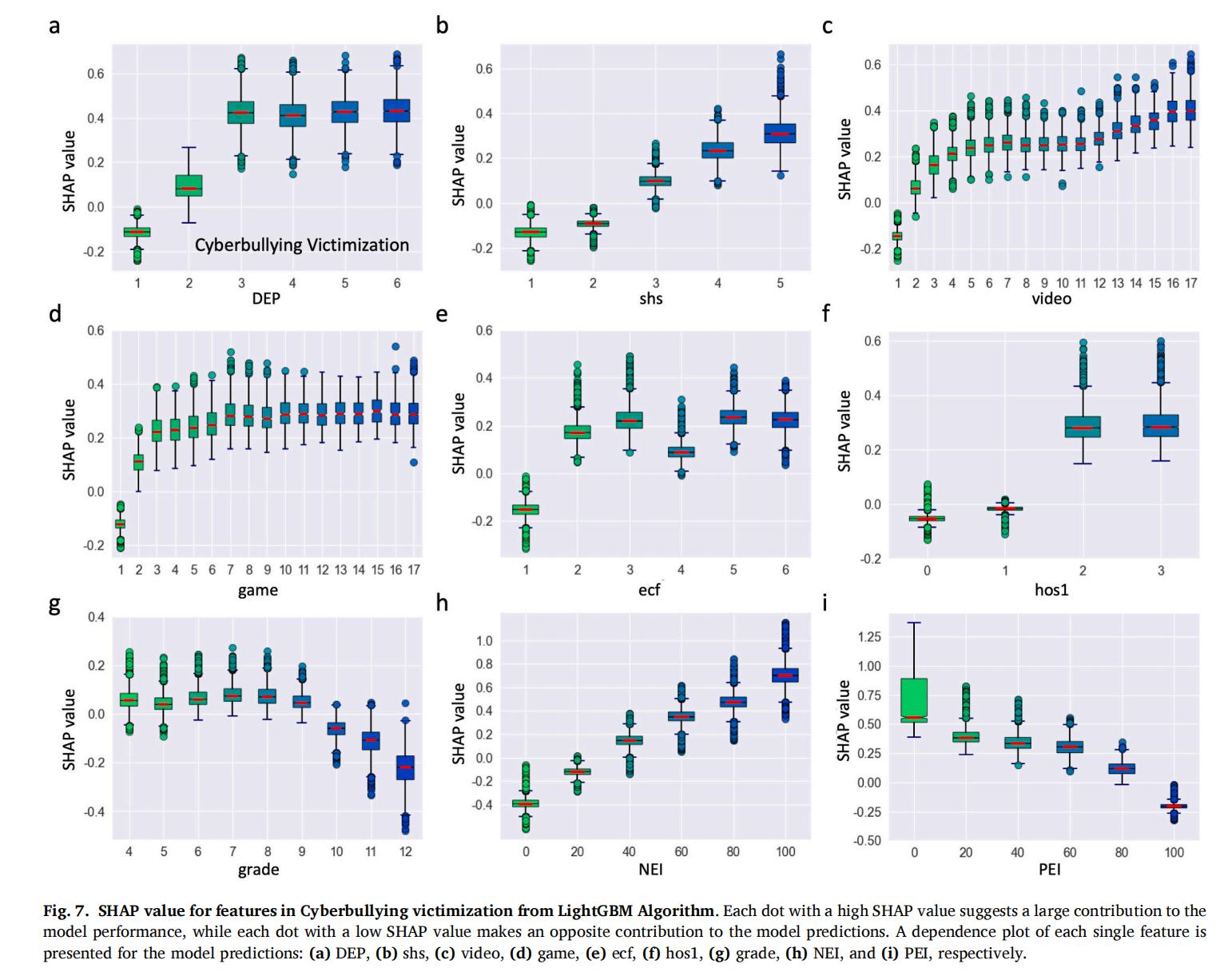
图7
图 7 表明抑郁程度更高(DEP≥2)、接触二手烟频率高(shs≥3)、每日观看视频时长超过半小时(video≥2)、媒体玩电子游戏超过半小时(game≥2)、参与线上课外班频率高(ecf≥2)、就医和服药频率较高(hos1≥2)、低年级(grade≤9 )、消极体验指数较高(NEI≥40)且积极体验指数较低(PEI≤80)是识别学生网络欺凌受害更重要的9个风险因素。
四、局限性
(一)样本的随机选择性
研究数据集是从某个教育合作项目中获取的,而不是对学校的抽样调查,存样本选择性偏差问题,可能无意中减少了潜在欺凌受害者的数量。后续研究开展需要更多随机选择的样本。
(二)截面数据难以识别因果关系
截面数据难以进行因果推断,后续可进行纵向研究获取面板数据,研究风险因素与受欺凌学生之间的因果关系。
五、想到了什么?
(一)在受校园欺凌的风险因素中,个体因素更重要还是环境因素更重要?
从研究结果看,在容易受欺凌的风险因素中,个体因素显著高于家庭、学校、同伴等外部因素,其中个体身心健康状况因素的贡献最大,这与以往研究中“个体脆弱性是欺凌受害核心因素”的结论一致。
社会生态系统理论强调个体发展嵌套于相互影响的环境系统之中。该理论将社会环境视为一种社会性的生态系统,注重人与环境间各系统的相互作用,揭示了家庭、社会系统对于个人成长的重要影响。因此也有很多研究显示家庭与内外部环境因素占主导作用,例如家庭社会经济地位低的学生更容易受到校园欺凌,家庭社会经济地位对城乡学生各类欺凌他人行为均具有显著的负向影响,且这种影响不存在城乡异质性。(周镭,李佳哲,2023)这与社会生态系统理论强调“个体的发展和行为是个人与环境系统持续相互作用的结果”的观点一致。该研究中的个体生活环境因素同样是增加欺凌受害的重要风险因素。
(二)个体因素和外部因素变量数量不同是否会导致统计偏差?
虽然模型中包含了40个风险因素,但纳入模型的个体因素数量有28个,远多于外部因素12个,易受校园欺凌的高风险外部因素如学校环境(氛围)、师生关系、父母教养方式等外部因素未被测量,在统计分析中可能在一定程度上强化了个体因素的重要性。
(三)在以学习为主导的学校环境中,成绩好坏是否影响学生受校园欺凌的频率?
该研究没有涉及到学生成绩,以往有很多研究表明成绩差也是未成年学生受到校园欺凌的重要因素。
论文链接
Yan, W., Yuan, Y., Yang, M., Zhang, P., & Peng, K. (2023). Detecting the risk of bullying victimization among adolescents: A large-scale machine learning approach.Computers in Human Behavior, Article 107817. https://doi.org/10.1016/j.chb.2023.107817
茗琰对这篇研究的方法设计梳理得很清晰,特别是你注意到个体与外部因素变量数量不平衡可能导致统计偏差,这个观察很敏锐。顺着这个思路,如果后续研究想更公平地比较两类因素的贡献,你会建议在数据收集阶段就刻意平衡变量数量,还是通过统计手段(如加权)来校正?另外,你提到的成绩变量未被纳入,若加入后,你觉得机器学习模型的特征重要性排序会如何变化?
我会优先在数据收集阶段注意平衡变量数量,再用统计方法做二次校正。机器学习模型(随机森林、LightGBM)对变量维度、特征数量比较敏感。未来可按照生态系统理论分层设定变量数量:个体因素:家庭因素:学校因素:同伴因素 = 1:1:1:1。
传统计量模型变量有限、难以捕捉非线性关系和多层交互效应,而机器学习依托大样本挖掘变量重要性,刚好能弥补传统实证的短板。而且现实里线上线下欺凌高度联动、叠加风险突出,只单独研究某一类早就不够了。区分两类欺凌的高低风险人群,既能厘清复杂成因,也能给校园精准防治、提前干预提供特别落地的参考,这个研究视角特别有现实意义
这个研究的样本量很大,41万的大样本用传统的分析方法确实会花时间精力,用机器学习做欺凌风险识别就很合适,而且这个选题也很有现实意义。六种算法对比、特征重要性和SHAP分析都做得很扎实,清晰找出抑郁、消极经历、屏幕时间、二手烟等关键风险因素,很清晰直观。也想了解如果加入成绩(帖子里提到的)、师生关系这些变量,模型效果会不会进一步提升
这篇论文最大的亮点是不只用一个算法硬跑,而是拿六种机器学习算法(比如随机森林、LightGBM)挨个试了一遍,发现随机森林和LightGBM表现最好,准确率能到90%以上。更新颖的是研究者把这两个算法的结果揉在一起,搞了个“组合模型”,预测谁可能被欺负,准确率更高。而且用了一种叫SHAP的方法,把黑箱模型“掰开”解释——不光告诉你哪些因素重要,还能看出这些因素是朝哪个方向影响的,比如积极情绪越多、受欺负风险越低。
但是通过阅读发现,该研究的数据是横截面的,就是说同一时间点测量的,所以没法说谁是因谁是果——是抑郁才被欺负,还是被欺负才抑郁?另外欺凌受害的测量依赖少量自陈题项,可能存在报告偏差;虽然纳入了40个变量,但部分重要社会生态因素(如师生关系、教养方式)未包含;样本中个体层面因素远多于社会层面,可能无意中削弱了后者的相对重要性;且数据源于积极心理教育项目,对潜在受害者的覆盖可能不够随机。
我觉得同学对这篇研究梳理的很细致清晰,是一篇大样本、方法前沿、现实价值极高的校园欺凌量化研究,用机器学习完美解决了传统统计的短板,精准识别了两类欺凌的风险与保护因素,非常适合教育管理、学校心理防控、青少年健康领域参考。但是这个研究是不是缺失关键外部变量,例如师生关系、校园氛围、父母教养方式、班级人际氛围等,这些都是欺凌研究的核心变量,缺失会导致风险因素识别不完整。
这篇文章将机器学习引入到了校园霸凌识别中,具有很强的现实意义,大样本可以选择机器学习,小样本可以用传统统计,在变量的选取上面也充分考虑到了可获取性,本文做的还是一个分类问题,对会不会收到校园霸凌做了一个2分类,但是由于本研究只采取了同一时间的数据,可能只能分析到相关性,不能推断出因果关系
样本非随机可能遗漏潜在受害者,未纳入成绩、师生关系等关键变量,大概率会放大个体因素的重要性,导致结论存在偏差。技术的核心是服务现实,精准识别之外,完善样本与变量设计,才能让研究结论更具参考性,真正为校园欺凌防治提供有效支撑。
目前很多截面数据很难发表论文了,得上一些机器学习的方法,不过也确实存在难以识别因果关系的问题。然后这篇论文的样本量也确实非常大,不是一般课题组可以拿到的数据