
-
导语
“普通笔记本电脑也能跑出数亿参数的实时模型?这不再是天方夜谭!”
在高维数据席卷全球的背景下,高斯过程(GP)凭借其强大的非参数建模能力和精准的不确定性量化,成为复杂系统辨识、实时感知等领域的核心工具。然而,传统高斯过程面临着致命的“维度灾难”——计算复杂度随数据规模呈立方级增长。虽然张量网络(Tensor Networks)技术的出现初步解决了高维度下的存储瓶颈,但其在数值稳定性上的天然缺陷往往导致模型在长时间运行后崩溃。
本帖子将深度拆解张量网络平方根卡尔曼滤波器(TNSRKF),为您打开一扇全新的技术之窗。该方法通过创新的“平方根因子”表示法,不仅彻底解决了传统张量网络滤波的发散问题,更实现了在标准个人电脑上对414(约 2.68 亿)个参数进行实时估计的壮举。如果您关注高维实时学习或非线性系统辨识,本报告将
-
方法的基本信息
核心思想
该方法的核心思想是将高斯过程回归(GP Regression)转化为一种在线参数估计问题,并结合卡尔曼滤波(Kalman Filter)的递归思想进行状态更新。创新的关键在于:它不直接维护巨大的协方差矩阵Pt,而是转而维护其平方根因子Lt(使得Pt = LtLtT )。
通过将这种平方根因子表示为张量列阵矩阵(Tensor Train Matrix, TTm)格式,算法能够利用张量分解的紧凑性大幅降低计算量。在递归过程中,利用交替线性方案(Alternating Linear Scheme, ALS)进行优化更新,并辅以张量 QR 分解技术维持数据的正交性与维度稳定。
独特价值
- 绝对的数值稳定性:传统张量网络卡尔曼滤波器(TNKF)在执行张量舍入(Rounding)操作时,极易导致协方差矩阵失去正定性(Positive Definiteness),从而引发模型发散。TNSRKF 通过平方根因子的物理结构,从数学根源上保证了协方差矩阵始终是半正定的,极大地增强了滤波器的鲁棒性。
- 打破维度灾难:利用张量列阵(TT)分解,将存储和计算复杂度从随输入维度D指数增长降为线性增长(O(D))。这意味着以前需要超级计算机才能处理的高维特征空间,现在可以在笔记本电脑上实时运行。
- 计算与精度的平衡:研究证明,在全秩(Full-rank)张量设置下,该方法与标准卡尔曼滤波完全数学等价;而在低秩近似下,它能以极小的精度损失换取巨大的计算提速。
关键产出
- 后验分布参数:实时更新的权重均值wt(TT 格式)与协方差平方根因子Lt(TTm 格式)。
- 高性能预测模型:能够针对未见过的测试输入,实时给出预测均值及其不确定性区间(预测方差)。
- 验证基准:在非线性级联水箱(Cascaded Tanks)等复杂工业基准数据集上表现优异。
-
方法的操作过程
3.1 应用原则
- 低秩先验:假设高维权重的动态关联结构可以通过低秩的张量网络来捕捉。
- 递归逻辑:遵循“先预测、后修正”的卡尔曼滤波闭环,确保每一时刻的后验分布都能作为下一时刻的先验。
- 正交性维持:通过QR步(SVD截断)操作,确保平方根因子在列数增长时能够被有效地压缩和重新正交化。
3.2 具体操作步骤
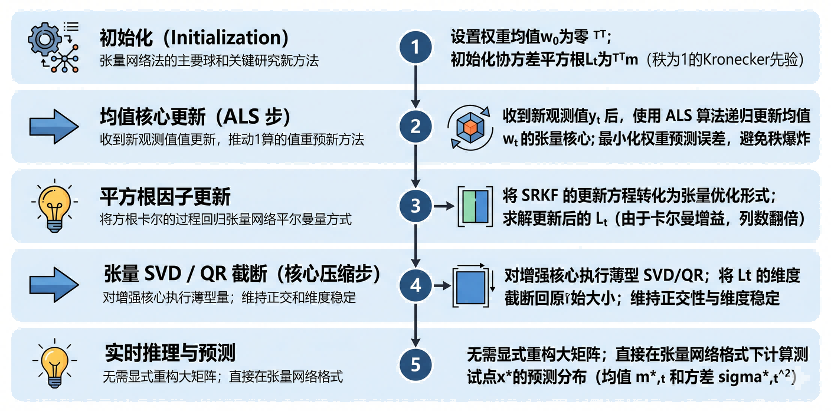
第一阶段:系统初始化
- 特征映射:选择合适的乘积核函数(如 RBF 核),将D维输入映射到特征空间。
- 张量初始化:将初始均值w0设置为全零TT,并将初始协方差根据核函数结构初始化为秩为1的TTm格式。
第二阶段:递归在线更新(针对每一时刻的新观测值yt)
- 均值核心更新(ALS 步):
- 通过最小化二范数残差的优化问题,采用 ALS 方案逐核心(Core-by-core)地更新均值的张量分量。
- 这一步避免了在更新过程中出现张量秩(Ranks)的急剧爆炸,维持了计算效率。
- 将 SRKF 的更新方程转化为张量优化形式。
- 此时产生的中间张量L的列维度会因为卡尔曼增益的引入而增加。
- 关键动作:由于L的列数在更新后会翻倍,必须执行一个基于SVD的压缩操作(Algorithm 2)。
- 通过对增强核心执行薄型SVD,将维度截断回初始大小,这一步确保了算法的长期可持续运行。
第三阶段:实时推理与预测
- 直接计算:无需重构数亿维度的权重向量,直接利用张量核心的收缩(Contraction)操作计算测试点的均值和方差。
- 不确定性量化:通过平方根因子的内积直接得到预测方差,为自动驾驶或过程控制提供“置信度”参考。
3.3 数据分析方法
- RMSE 指标:用于衡量预测均值与真实物理观测值之间的绝对误差。
- NLL 指标(负对数似然):这是评估高斯过程性能的关键,不仅看预测得准不准,还看预测的不确定性估算是否合理。
- 秩敏感性分析:通过调整张量秩(Rw和RL),分析计算开销与预测精度之间的权衡曲线。

-
方法的应用启示
适用情境
- 大规模在线系统辨识:适用于参数规模达到百万甚至亿级,且需要实时更新模型的复杂动力学系统(如工业反应器、飞行模拟)。
- 资源受限的边缘计算:在嵌入式系统或普通 PC 上运行原本需要大型服务器的 GP 模型。
- 非平稳环境监测:由于卡尔曼滤波的递归特性,该方法非常适合追踪随时间变化的系统参数。
个人思考
TNSRKF 的成功证明了一个深刻的观点:物理系统的复杂性往往具有隐藏的结构。虽然特征空间的维度可能是天文数字,但有效的因果路径通常存在于低维张量流形上。该论文最大的贡献在于将“数值稳定性”作为最高准则,引入平方根滤波。在实际工程中,算法的收敛性往往比单纯的精度提升更重要。对于研究者而言,这启发我们:在追求大规模学习时,必须回归数值分析的基础,利用数学结构的对称性(如平方根)来对冲近似计算带来的风险。
值得探讨的新问题
- 自适应张量秩(Adaptive Ranks):目前的算法仍需预设秩的大小。未来是否可以实现根据误差实时调整张量秩?
- 与深度特征学习结合:是否可以将深度神经网络作为特征提取的前端,后端接入 TNSRKF 进行不确定性量化?
论文信息
Menzen C, Kok M, Batselier K. Tensor network square root Kalman filter for online Gaussian process regression[J]. Automatica, 2026, 183: 112694.
乙文对TNSRKF中平方根因子保证数值稳定性的剖析非常到位,这确实是工程落地的关键。顺着这个思路,如果将该方法迁移到非平稳系统或在线迁移学习场景,协方差结构的突变可能使固定秩假设失效——能否通过引入秩自适应机制(如基于预测误差的阈值截断)来动态平衡精度与效率?这或许能进一步拓展其在高动态环境下的适用边界。
是的老师,固定秩假设在平稳环境下能极大地压缩计算量,但在非平稳系统(如高动态无人机轨迹预测或在线迁移学习)中,其确实难以捕捉协方差结构的突变。引入秩自适应机制确实可以实时监测创新向量的范数。当预测误差超过预设阈值时,利用奇异值分解(SVD)或张量分解的残差项动态增加秩,以捕获突发特征,防止滤波发散。在误差平稳期时,可以通过控制奇异值能量占比进行截断,剔除冗余噪声,恢复计算效率。这种按需分配的逻辑可以实现算法在高精度追踪与轻量化部署间的动态最优博弈,是一个很好的拓展方向。
看到你的看法:在实际工程中,算法的收敛性往往比单纯的精度提升更重要。对于研究者而言,这启发我们:在追求大规模学习时,必须回归数值分析的基础,利用数学结构的对称性(如平方根)来对冲近似计算带来的风险。不得不说非常认同,要对自己的数据进行客观和科学的处理,得出有效的结论。