
《Utilising causal inference methods to estimate effects and strategise interventions in observational health data》
一、导语
在教育与社会科学研究中,我们常常面临一个现实困境:由于预算或者是伦理问题,无法开展随机实验,只能用观察数据,却又希望回答“某种教学或干预是否真正有效”这一因果问题。
来自 PLOS ONE 的这篇研究,提供了一种前沿解决方案——将因果推断与机器学习相结合,在观察数据中识别干预效果,并进一步优化干预策略。
而且,这篇文章不仅回答“是否有效”,还回答了:“对谁最有效?”以及“如何更精准地实施干预?”
二、方法的基本信息
该研究基于因果推断(Causal Inference)框架,结合机器学习方法,提出了一种在观察数据中估计干预效果的分析路径。其核心包括三个层次:
- 平均处理效应(ATE):整体上干预是否有效
- 条件处理效应(CATE):不同人群效果是否不同
- 干预策略优化:如何分配干预以获得最佳效果
2. 独特价值
与传统统计方法相比,该方法具有三点突出优势:
- 突破相关性分析局限: 从“变量相关”走向“因果解释”
- 识别个体差异(异质性):不再只关注平均效果,而是关注“谁受益更多”
- 支持决策优化:不只是解释现象,还能指导“如何实施干预”
3. 关键产出
- 提供了一套基于因果树与因果森林的分析框架
- 实现了从数据中自动识别“高收益人群”
- 构建了最优干预策略模型
👉 实质上,这是从描述研究走向决策研究的重要一步。
三、方法的操作过程
1. 应用原则
该方法主要适用于:
- 无法开展随机实验(RCT)的研究情境
- 存在混杂变量(confounding)的观察数据
- 需要分析“差异化效果”的问题
2. 操作步骤
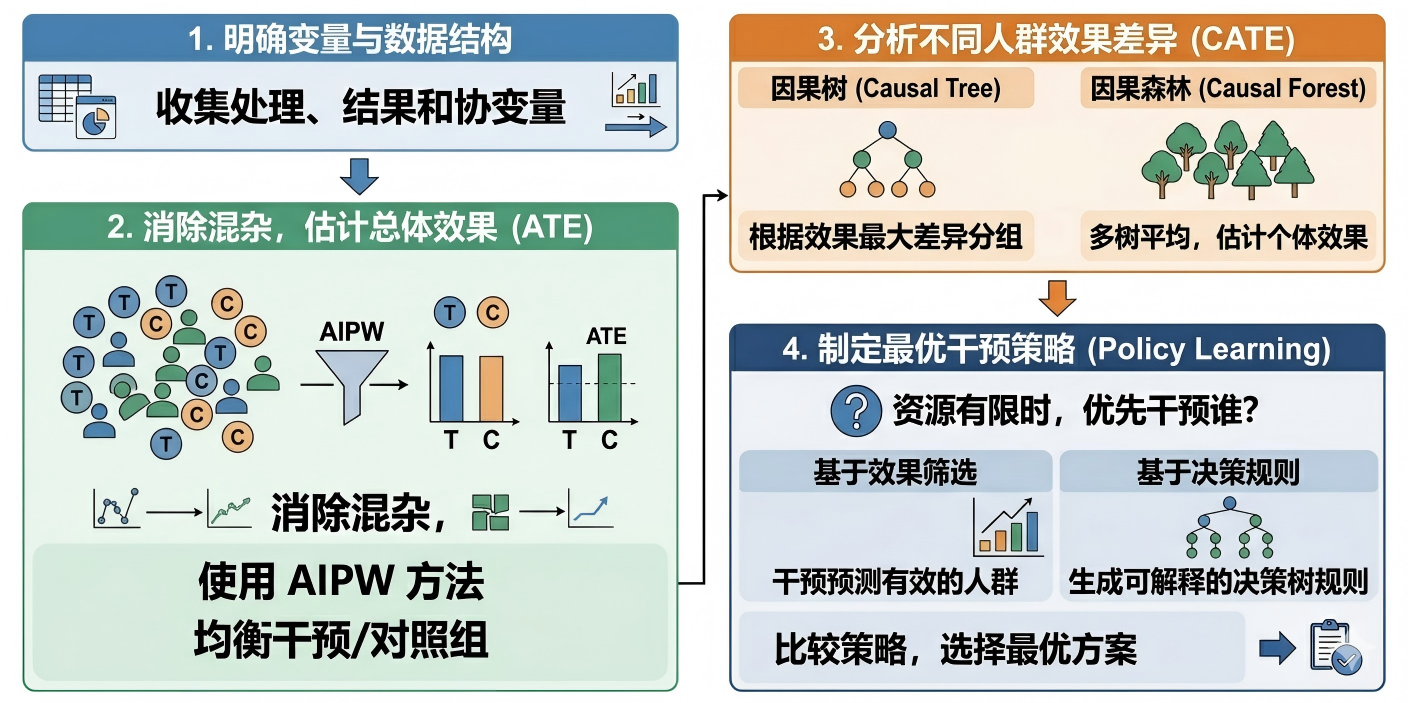
Step 1:明确变量与数据结构(研究准备)
- 收集观察数据(包含处理变量、结果变量、协变量)
- 明确“干预(treatment)”与“结果(outcome)”
Step 2:控制混杂变量,估计总体效果(ATE)
由于观察数据中“谁接受干预”不是随机的,会产生偏差,因此需要先进行调整。
- 使用AIPW方法(双重稳健估计),同时结合结果模型和倾向得分模型:消除混杂变量影响,使“干预组”和“对照组”更可比
- 输出结果:ATE(平均处理效应), 来回答:“总体来看,干预是否有效?”
Step 3:分析不同人群的效果差异(CATE)
在得到整体效果之后,进一步分析:不同人群,效果是否不同?
(1)因果树(Causal Tree)
- 自动根据数据对人群进行分组
- 分组标准:让“不同组之间的效果差异最大”
👉 结果:得到不同子群体的效果(CATE)
(2)因果森林(Causal Forest)
- 构建多个因果树并进行平均
- 类似“随机森林”的思想
👉 优势:结果更稳定、可以估计个体层面的效果
Step 4:制定最优干预策略(Policy Learning)
在知道“谁更有效”之后,进一步解决一个更实际的问题:资源有限时,应该优先干预谁?
(1)非参数策略(基于效果筛选)
- 只对“预测有效的人群”实施干预
👉 特点:简单直接,效果最好
(2)参数策略(基于决策规则)
- 用决策树生成“干预规则”(例如:某类学生优先干预)
👉 特点:更容易解释、更适合实际应用
👉 最终输出:
比较不同策略下的整体效果,选择最优方案
四、方法的应用启示
1. 适用情境
- 教学实验(如不同教学方法效果比较)
- 教育政策评估
- 心理或行为干预研究
- 医疗与公共健康研究
2. 对教育研究的启发
(1)从平均效果走向差异化效果
在以往的教育研究中,大家往往关注某种教学方法整体是否有效,比如比较实验班和对照班的平均成绩差异。但这篇研究提醒我们,真实情况往往更复杂,不同学生对同一种教学方式的反应可能差别很大。因此,在开展教学实验时,可以不只停留在整体比较上,还可以进一步分析不同类型学生的变化情况,比如基础较弱和基础较好的学生是否受益不同。这样的分析更贴近真实教学情境,也更有助于理解教学效果的内在机制。
(2)让观察数据也能更可靠地支持结论
在教育研究中,很难做到完全随机分组,很多时候只能依赖已有数据来进行分析。但这样容易受到学生背景差异的影响,导致结论不够可靠。这篇研究提供了一种思路,通过倾向得分和AIPW等方法,对数据进行调整,让不同组之间更具有可比性。对我们来说,这意味着即使是在自然班级或真实课堂环境中开展研究,也可以通过合理的方法提升分析的严谨性,让研究结果更有说服力。
(3)从评估效果走向改进教学决策
很多研究做到最后,往往只是得出某种方法是否有效的结论,但很少进一步思考如何用这些结果指导实际教学。这篇研究更进一步,通过分析不同人群的效果差异,提出可以把资源优先用在更可能受益的对象上。这一点对教学很有启发,比如在课堂中,可以根据学生特点进行更有针对性的支持,而不是采用完全一致的教学方式。这样不仅能提高教学效率,也更符合因材施教的理念。
3. 值得进一步讨论的问题
欢迎大家思考和讨论👇
- 在教育研究中,如何界定“处理变量”(treatment)?
- 因果推断方法对样本量有什么要求?
- 在小样本教学实验中,是否适合使用因果森林?
- 如何将该方法与课堂实际教学结合?
五、论文基本信息
APA格式:Duong, B., Senadeera, M., Nguyen, T., Nichols, M., Backholer, K., Allender, S., & Nguyen, T. (2024). Utilising causal inference methods to estimate effects and strategise interventions in observational health data. PLOS ONE, 19(12), e0314761.
标签:因果推断 观察性研究 机器学习 教育量化研究 异质性分析 精准干预
源文档:通过网盘分享的文件:journal.pone.0314761.pdf 链接: https://pan.baidu.com/s/19WevNBkfxR7GPuW6CzW8pg?pwd=67es 提取码: 67es
美松对因果推断与机器学习结合的价值梳理得很清楚,尤其是从ATE、CATE到策略学习的层层推进,把“是否有效”转向“对谁有效”和“如何干预”。顺着这个思路,如果把该方法用到小样本教学场景,因果森林对异质性的捕捉是否会过度依赖噪声?这也提醒我们,精准干预不只要算得出,还要解释得稳。
这篇文章最吸引我的地方,是它不只问干预有没有效果,还进一步关注对谁最有效。这种思路很适合教育研究,因为学生差异很大,平均效果往往容易掩盖个体差别。文章把因果推断和机器学习结合起来,用观察数据尽量接近因果解释,对真实课堂研究很有启发。不过我也觉得,这类方法对样本量和数据质量要求较高,小规模教学研究使用时还需要谨慎。