
一、导语
在短视频、AI生成内容和多模态数据爆炸的时代,你还在用“单一文本分析”研究复杂现象吗?当研究对象从“文字”走向“图像+声音+视频”的多模态世界,传统量化方法开始失效。近十年逐渐发展成型的多模态内容分析法(Multimodal Content Analysis, MCA):一种融合定量分析与社会符号学的前沿方法,能够真正实现大规模、多模态数据的结构化量化研究。
👉 如果你的研究涉及:AI、短视频、课堂行为、学习过程分析——这个方法值得认真看。
二、方法的基本信息
1. 核心思想
多模态内容分析法的本质是:将“多模态数据(语言、图像、声音)”转化为“可量化变量”,并进行系统统计分析与意义解释。即实现:复杂多模态现象 → 编码 → 数据化 → 统计分析 → 意义解释
2. 独特价值(为什么是“前沿”)
✔ 突破1:从“小样本质性” → “大规模量化”
传统多模态研究:
- 个案分析
- 主观解释
该方法:
- 大规模语料(如1400条视频)
- 可重复、可验证
✔ 突破2:打破“定性 vs 定量”对立
该方法融合:
- 定量内容分析(统计)
- 定性解释(社会符号学)
👉 属于:混合研究方法(Mixed Methods)的前沿形态
✔ 突破3:分析对象升级
传统研究对象:
- 文本
该方法:
- 语言 + 图像 + 声音 + 视频
👉 面向:数字时代真实数据形态
3. 关键产出
该方法可以输出:
- 多模态特征分布(频次、比例)
- 模态之间的关系结构
意义建构机制(深层解释)
三、方法的操作过程
1. 方法应用原则
- 理论驱动(社会符号学)
- 编码标准化(变量+值)
- 定量与定性结合
- 信度检验保障科学性
2. 核心操作步骤
Step 1:提出研究问题
- 强调“可量化问题”
Step 2:构建多模态数据库
- 视频 / 图像 / 文本
Step 3:建立编码体系(核心步骤)
定义:
- 变量(variable):
- 语言变量
- 视觉变量
- 听觉变量
- 值(value):
- 每个变量的分类
Step 4:编码与标注
- 使用工具(如ELAN)
- 多人编码
Step 5:信度检验
- Kappa系数(>0.8)
Step 6:量化分析
- 频次统计
- 对比分析
Step 7:意义解释
-
- 社会文化分析
- 符号机制解释
3. 方法流程图
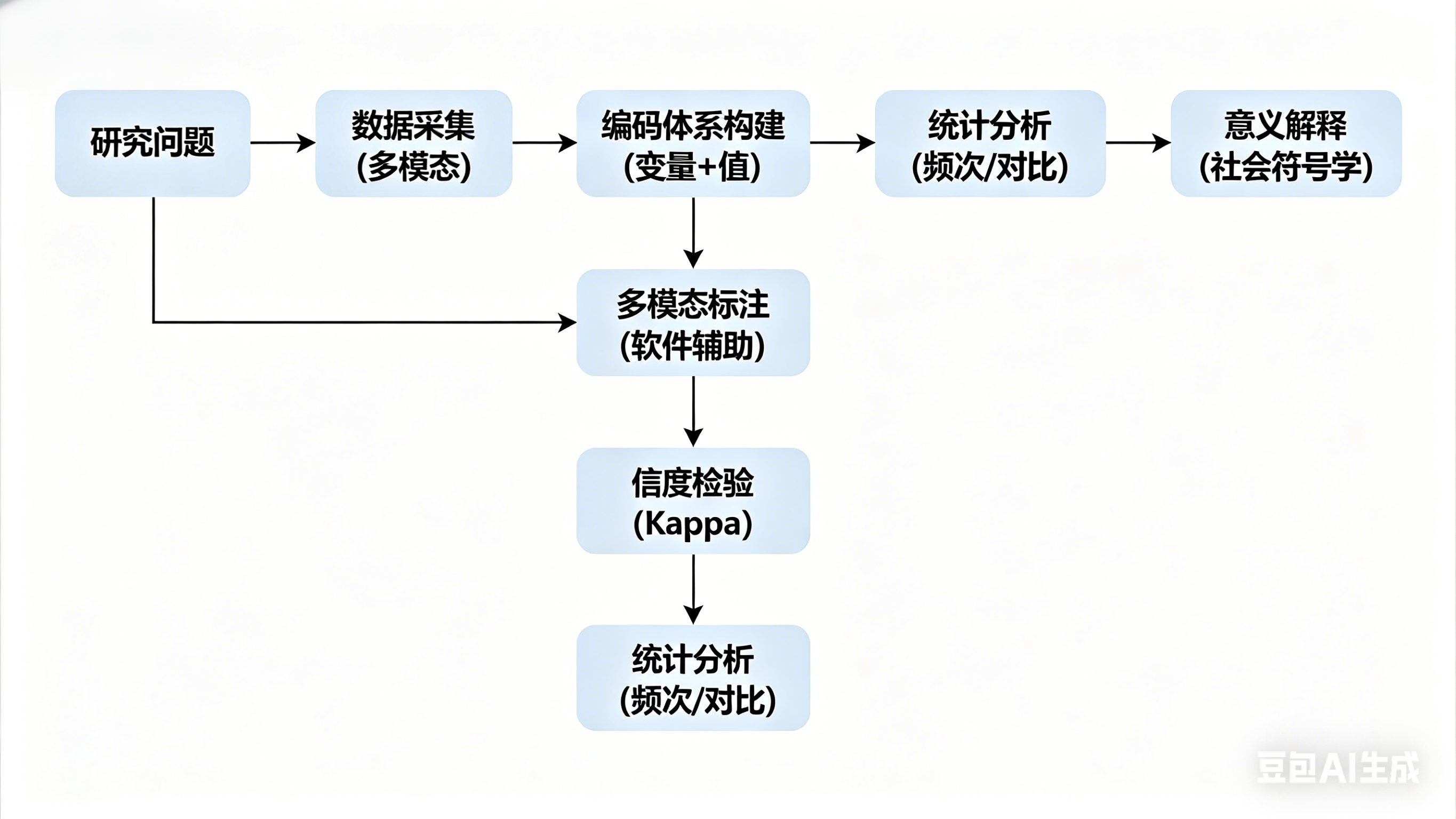
四、应用案例分析
这是一个运用多模态内容分析法,对大规模(1400条)城市宣传短视频进行系统性编码与量化分析的实证研究。它完美展示了该方法如何融合“定量广度”与“定性深度”。
4.1 研究问题、研究对象及数据来源
近年来,国内各城市借助抖音平台,积极探索城市形象塑造的创新路径,涌现出一批新晋网红城市。本研究旨在运用多模态内容分析法,以西北内陆城市西安与东南沿海城市深圳为典型案例,系统分析两者在城市形象建构方面的异同。基于对城市形象相关文献的梳理,我们发现学界对中国城市的讨论主要集中在“传统城市形象”与“现代城市形象”两大维度。据此,我们提出以下两个研究问题:1)西安与深圳在抖音宣传视频中呈现出怎样的城市形象?2)这两类城市形象特征是通过何种符号资源建构的?
为回答上述问题,本研究抓取了西安文旅、i游深圳自2018年5月开始发布视频之日至2023年9月在抖音平台上发布的794条与823条短视频数据。在剔除重复、失效视频后,分别生成758条与793条视频研究样本。为确保两个城市宣传视频样本的可比性,我们进一步选取了各自点赞量最高的700条视频作为最终分析对象。这1400条视频的音频总时长超过41.45小时,转写为文本后合计约1.7万字。
4.2 建构编码框架
根据研究问题,本研究将整个编码环节分为两个层面:第一层面旨在归纳并提炼传统城市与现代城市的具体形象特征;第二层面分析城市形象特征的多模态符号建构方式。首先,我们将城市形象看成不同种类的评价意义,例如时尚、历史悠久、文化深厚等。这一层面的分析采用归纳式内容分析法:两位编码者对1400条抖音视频逐一进行内容分析,经由开放式编码,在“传统城市形象”与“现代城市形象”的内容变量下得出尽可能多的分析子变量,并对出现歧义的子变量概念进行反复调整。
分析的第二个层面遵循演绎分析法,围绕识别不同符号的实现方式展开。基于社会符号学理论,我们设计出一个编码方案(如表2所示),用来分析各变量中的不同值。该表最显著的特征是其区分出语言设计值、视觉设计值与听觉设计值。就语言设计值而言,我们关注两个子值,即显性评价值与隐性评价值。显性评价值指直接的态度词汇表达,如现代、传统、年轻等;隐性评价值一般通过叙述引发态度的事实这一方式实现。例如,通过“西安被称为十三朝古都”这一表述构建西安“传统城市”形象。
表2 城市形象与不同符号实现方式的关系

城市形象变量还可以通过视觉设计值得以实现。这一维度具体包括三个子值,即角色设计、场景设计以及特效设计。角色设计可以细分为动作过程与分析过程。动作过程是指不同角色在视频中的动作、手势、舞步等;分析过程是指角色的外形、着装、配饰等。场景设计指的是指选取何种场景作为视频的背景。比如,深圳城市宣传视频可以通过拍摄年轻时尚的网络意见领袖(角色设计)在当地五星级酒店(场景设计)喝下午茶构建现代化的城市形象。特效设计是指抖音平台推出的一系列视频特效,帮助用户进一步加工、重构整体的视频风格。比如,网红可以通过“磨皮”“大眼”等方式美化自身形象,建构“青春时尚”的特征。
该研究的第三个变量是听觉设计资源。正如Machin & van Leeuwen(2007:413)所强调的,声音和音乐应被视为“具有独特表达力的符号资源,具备自身的可供性(affordance)”。借助van Leeuwen(1999)的声音符号理论,我们将抖音视频中的听觉模态分为两个子值,即前景声音(Figure)与背景音乐(Ground)。其中,前景声音指的是“观众注意力的聚焦点,即显著的声音信号”(van Leeuwen1999:16),通常表现为角色配音或旁白;而背景声音则构成“声音景观”(soundscape),即“观众所处的听觉环境背景”(van Leeuwen 1999:17),多表现为背景音乐或环境音效。
在变量设定与编码系统构建完成后,研究进入量化分析环节。本研究采用交互信度检验,确保编码的准确性。该检验分两轮进行,间隔时间为一个月。两位编码者在明确编码表中内容变量及其对应值后,独立完成编码任务。本研究使用Kappa系数作为衡量编码一致性水平的统计指标。第一轮检验的Kappa值为0.81,这一数值被视为“几乎完美”的一致性水平(Landis & Koch 1977:165)。通过讨论解决编码分歧后,第二轮检验的Kappa值上升到0.94,进一步验证了编码体系的操作性与研究结果的信度保障。
4.3 量化结果分析
通过对深圳与西安共计1400条抖音短视频的系统性标注与分析,研究发现两地在城市形象建构策略上存在显著差异(见图2)。图中数值表示各类城市形象特征在样本视频中的出现频次(而非视频条数)。结果显示,深圳更侧重于“国际化”(315次)与“年轻时尚”(297次)形象的呈现,显著高于西安(90次、185次);而西安则更突出“传统文化”(247次)与“悠久历史”(289次),同样高于深圳(121次、86次)。然而,在多数宣传视频中,两座城市都并未孤立展现某一文化特征(如国际化、悠久历史等),而是通过融合现代性与传统性,构建出一种融汇中外、贯通古今的“超文化”城市形象。在具体建构方式上,深圳与西安普遍采用隐性评价话语与角色设计策略,呈现出高度相似的叙事路径(见表3)。在语言设计层面,隐性评价在深圳与西安的短视频中分别出现254次和271次,占据主导地位;在视觉设计层面,角色设计共出现555次,明显高于场景设计的409次。接下来,本文将进一步分析两地在城市形象建构中的具体差异表现。
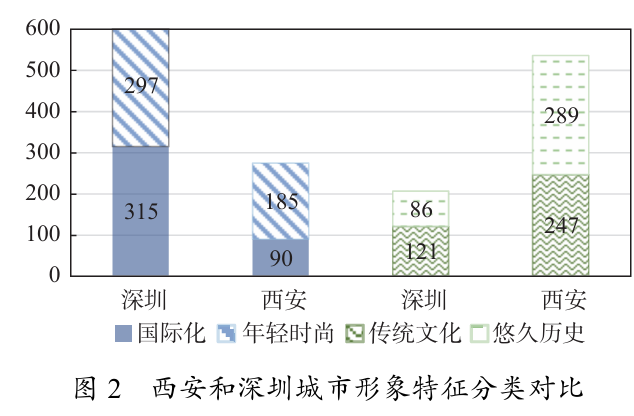
表3 西安和深圳城市形象特征建构方式分布
| 分类 | 深圳 | 西安 | 合计 | |
|---|---|---|---|---|
| 语言设计 | 显性评价 | 89 | 67 | 156 |
| 隐性评价 | 254 | 271 | 525 | |
| 视觉设计 | 角色设计 | 286 | 269 | 555 |
| 场景设计 | 194 | 215 | 409 | |
| 特效设计 | 21 | 9 | 30 | |
| 听觉设计 | 背景音乐 | 146 | 132 | 278 |
| 前景声音 | 83 | 107 | 190 |
分析发现,深圳在建构现代化大都市形象时,仍试图保留传统文化特色。在具体建构过程中,视频中并未出现以“国际化”或“年轻化”等显性评价性词语,而是通过角色设计实现隐性表达。在286条短视频样本中,网红通过发布“打卡”短视频,积极参与深圳热门景点的推广。具体而言,在分析过程与特效设计中,网红通过时尚穿搭(如皮夹克、百褶裙、马丁靴)与创意拍摄技巧(如动态镜头切换、光影效果),传递出深圳的青春气息;与此同时,在动作过程与场景设计层面,网红常在深圳历史古建筑前体验当地民俗活动、制作传统手工艺、品尝传统美食,借此间接构建出深圳传统的城市形象。如图3(左)所示,该视频体现出深圳“超文化”融合的核心策略:穿着时尚的年轻女孩作为视觉焦点,将现代化的城市形象前景化(角色设计);与此同时,其所身处的二十四史书院历史建筑(场景设计)将深圳的传统文化特征背景化。在听觉设计方面,深圳城市宣传短视频较多选用通俗化、大众化的流行音乐形式,拉近城市形象与普通观众之间的审美距离。
在西安现代化都市形象的建构中,宣传视频同样展现出融汇中外的“超文化”特征。就角色设计而言,这种文化融合主要通过来自世界各地的国际友人在西安体验当地特色民俗活动得以实现。例如,视频中呈现了国际友人品尝当地特色小吃、聆听秦腔戏剧、观赏皮影戏等场景,这些行为不仅凸显了西安作为历史文化名城的传统魅力,还通过跨文化互动传递了其国际化的现代都市形象。图3(右)呈现了一个典型的融汇中外的“超文化”案例。来自摩洛哥的驻华大使借“中国年”的契机,以中文向观众致以新年祝福,并双手作揖,展现出中国节日期间亲友互致问候的传统礼仪(动作过程);该视频以中国红为背景主色调,画面下方辅以舞狮、牡丹花、大雁塔等视觉元素,进一步强化中国传统文化意涵(场景设计)。在背景音乐选择上,宣传视频将陕西传统民谣进行流行化改编,融入轻摇滚与电子等现代编曲元素,有效构建出“年轻化”的城市形象,突破西安“历史古都”的单一文化想象。
在传统城市形象建构中,西安主要通过场景设计重塑古代长安的繁荣景象。289个视频以“一点灯,西安就回到了长安”为标题,采用长镜头拍摄技术,展现夜色中西安历史名胜古迹的恢弘景象。如下页图4(左)所示,灯光秀通过光影的巧妙运用,将西安古城墙的繁华表现得淋漓尽致,唤起了观众对历史记忆的共鸣。在角色设计方面,西安通过将历史名人(如李白、杜甫)以及传统文化形象(如兵马俑、唐仕女、羽林军)重新塑造为亲切可爱的卡通人物,赋予其现代化审美特征。在声音风格方面,这些“活化”的文物常采用具有“二次元”特征的配音风格进行拟人化呈现。高音调、跳跃式的情绪表达使其在听觉上更具亲和力与趣味性,从而重构了西安传统文化传播的语境。深圳在传统城市品牌的塑造中积极撕去“文化沙漠”的刻板印象,打造具有商业活力的“古镇形象”。121条视频挖掘深圳周边的各大古镇文化符号,通过展示茶馆、老墙、旧居、石桥等特色景观符号(场景设计),体现古镇的历史底蕴。如图4(右)所示,深圳抖音短视频通过镜头聚焦古镇的长街与街道两侧的老字号商铺,展示了其丰富的非物质文化遗产和质朴含蓄的人文景观。在听觉设计方面,75条宣传视频使用低沉、吟诵式语调,唤起观众对“过往时代”的联想,营造出厚重的历史氛围。
五、方法的应用启示
1. 适用情境
该方法特别适用于:
✔ 教育研究
- 课堂行为分析(视频)
- 学习投入(行为+语言+表情)
✔ AI与数字教育
- AI对话分析(文本+语音)
- 多模态学习环境
✔ 新媒体研究
- 短视频(抖音/B站)
- 社交媒体传播
2. 对你研究的可能启示
你的研究:
- 跨学科课程
- 学习投入度
- 课堂观察
👉 可以升级为:“多模态学习投入分析”
例如:
|
模态 |
数据 |
|
语言 |
学生发言 |
|
行为 |
操作行为 |
|
情绪 |
表情/参与度 |
3. 值得进一步讨论的问题
- ❓ 多模态数据如何自动化编码?(AI能否替代人工?)
- ❓ 多模态分析与机器学习如何结合?
- ❓ 是否可以构建“实时学习分析系统”?
祥瑞对多模态内容分析法的系统性梳理非常清晰,尤其是将社会符号学与定量编码融合的框架设计,为大规模多模态研究提供了可操作的路径。顺着这个思路,如果将该方法迁移到课堂行为分析中,如何确保编码体系能有效捕捉非言语模态(如手势、眼神)的即时性意义?例如,学生微表情的短暂变化是否可能被现有编码粒度遗漏?这或许需要引入更细化的时间戳或动态特征变量,你对此有何考虑?
可以引入时间戳和动态变量,比如用ELAN软件分层标注微表情的起止时长、变化速度。结合人脸识别预检测+人工复核,就能捕捉到转瞬即逝的皱眉、眼神闪躲等,不必担心编码太粗漏掉关键细节。
这篇分享让我对“多模态内容分析法”有了比较直观的认识。它不再局限于传统的文本分析,而是系统地将视频中的语言、图像、声音等不同模态的数据转化为可量化的编码和统计指标,并融合了定量分析的广度与定性解释的深度。这种方法突破了以往多模态研究偏重个案、主观性强的局限,让大规模、可重复的多模态实证研究成为可能。这种方法对教育技术研究尤其有启发——比如可以用它来分析学生的视频作品,或者在线讨论中使用的表情包、语音语调等多模态交互数据,从而更全面地理解学生的知识建构过程和情感表达。但是,这种方法需要严谨的编码框架,其设计需要深厚的理论功底,而且不同模态之间的交互机制复杂,如何避免编码时的主观偏差、如何高效处理海量音视频数据具有一定挑战。