
随着计算机科学(CS)与其他学科的交叉融合日益加深,越来越多非计算机专业学生开始学习编程。然而,现有研究在计算机专业与非计算机专业学生的编程学习差异方面仍存在空白。以往研究大多依赖结果导向评估,聚焦于终结性评价与问卷调查,难以揭示真实的学习过程及其差异。本研究在统一教学条件下,从过程导向视角对比计算机专业与数学专业两类编程新手群体,追踪其一整学期的成绩、学习投入与代码指标差异。
结果显示,本研究以混合教学班中 75 名编程新手为对象(数学专业 35 人、计算机专业 40 人),通过潜类别分析与自组织映射识别学生全学期的不同学习状态,并运用序列挖掘探究两组学生的学习轨迹与状态转移差异。研究发现:随着课程推进,学习投入与成绩的关联在不同专业间出现分化,偏离了普遍认可的正相关关系;在 “过度工程化” 状态学生的整学期代码指标分析中,两个专业群体呈现相反趋势;此外,计算机专业学生的形成性成绩与终结性成绩高度一致,而数学专业学生则表现出冷启动与学习回避现象。
结论表明,理解差异化学习轨迹对优化多样化学习者的教学设计至关重要。本研究发现,计算机专业学生的学习模式随时间推进愈发高效,代码复杂度逐步降低;数学专业学生则需要针对性策略克服冷启动与学习回避问题。代码指标能够为学生编程表现与学习模式提供有效参考,同时研究强调课程初期积极投入与计算思维培养的重要性。基于上述结论,本文为入门编程课程提出教学设计建议,并为编程教育领域的过程导向研究提供方法学贡献。
本文以过程性学习数据为基础,整合潜在类别分析、自组织映射与序列挖掘方法,构建了一套完整的学习轨迹量化分析框架,系统比较计算机与数学专业学生在编程课程中的学习状态、发展轨迹及行为差异。研究通过多维度行为数据揭示了不同专业学生的学习规律与典型问题,为学习分析、量化方法应用及差异化教学干预提供了可借鉴的研究思路与实践范式。
一、方法的基本信息
- 核心思想:以过程导向、以人为中心为核心,从成绩、学习投入、代码质量三个维度,利用连续12次过程性数据,动态追踪并比较不同专业学生的编程学习状态变化与轨迹差异。
- 独特价值:首次将潜在类别分析(LCA)、自组织映射(SOM)、序列挖掘三者结合,实现“分型—聚类—轨迹—对比”的完整量化分析链条,真正捕捉个体异质性与动态学习规律。
- 关键产出:学习投入类型划分、代码质量状态识别、全学期学习轨迹图谱、状态转移规律、跨专业学习差异特征。
二、方法的操作过程
应用原则:
- 过程性原则:使用连续多次形成性评估数据,而非单次结果数据。
- 以人为中心原则:聚焦个体学习轨迹,不被群体平均趋势掩盖差异。
- 多维度融合原则:成绩、投入、代码指标三者相互印证,提升结论可靠性。
- 动态演化原则:重点分析学习状态的转移与变化,而非静态截面比较。
操作步骤:
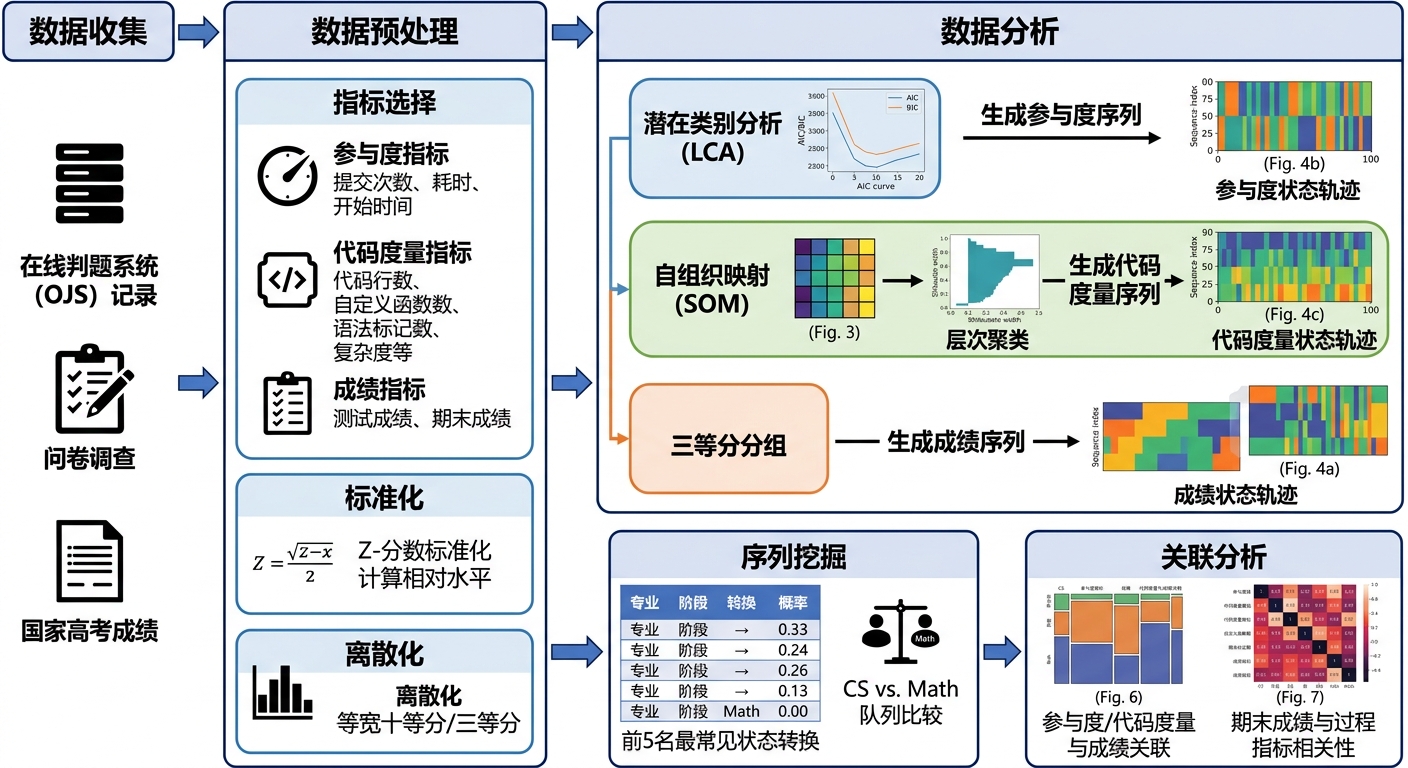
1、数据采集与预处理
- 数据来源:编程课在线评测系统(OJS),包含75名学生(CS40人、Math35人)的全学期数据。
- 核心数据:
- 成绩数据:12次形成性测验+1次期末考试分数
- 投入度数据:提交次数、耗时、开始答题时间
- 代码数据:圈复杂度、时间/空间复杂度、通过率等9项指标
- 预处理:数据标准化、离散化(三分法/十分位)、方差齐性检验。
2、投入度分型——潜在类别分析(LCA)
- 操作:使用LCA对投入度数据进行聚类,通过AIC、BIC指标确定最优类别数,最终将学生分为低、中、高投入三类。
- 目的:基于投入行为模式对学生进行分型,为后续轨迹分析提供基础。
3、代码状态聚类——自组织映射(SOM)
- 操作:对9维代码指标进行SOM降维聚类,将代码质量划分为“良好、中等、低下、过度工程”4种状态,并可视化在二维拓扑图上。
- 目的:将高维的代码数据转化为可解释的学习状态,为轨迹追踪提供状态标签。
4、构建学习轨迹——序列挖掘
- 操作:将每个学生12次测验的投入度类型与代码状态按时间序列排列,构建学习轨迹序列,计算不同状态之间的转移概率。
- 目的:动态追踪学生学习状态的演化过程,识别高频转移模式。
5、差异检验与可视化解读
- 操作:使用ANOVA、Kruskal-Wallis、Dunn事后检验比较不同专业学生的成绩、投入、代码指标差异;用马赛克图、折线图可视化轨迹模式。
- 目的:验证群体差异,直观呈现研究结果。
三、方法的应用启示
方法的适用情境:
- 编程/STEM课程的学习过程分析与学习轨迹研究
- 跨专业、跨群体学习差异的比较研究
- 在线学习行为数据、教育数据挖掘类研究
- 过程性评价、早期学习预警模型构建
个人思考:
这篇文献的研究方法最大的优势是从“结果评价”转向“过程理解”,它能发现问卷和单次成绩看不到的真实学习问题,比如“高投入低效率”“学习回避”“冷启动”,对教学干预极具价值。LCA+SOM+序列挖掘的组合范式,实现了“分型-聚类-追踪”的完整链路,为教育数据挖掘研究提供了一套可复制的模板。研究也提醒我们,在非CS专业的编程教学中,不能只关注成绩,更要关注学生的投入模式与代码质量,因为这两类指标能更早地预测学习风险。
值得探讨的新问题:
- 这套方法能否迁移到文科、商科等非STEM课程的学习轨迹分析中?
- 如何基于该方法构建编程课程的早期学习预警模型,提前干预高风险学生?
原文链接:https://link.springer.com/article/10.1186/s40594-025-00546-2
梦瑶对LCA、SOM与序列挖掘三者结合的量化分析框架梳理得非常清晰,尤其是从“结果导向”转向“过程理解”这一核心思想抓得很准。顺着这个思路,如果要将这套方法迁移到文科或商科课程,你认为需要调整哪些关键指标?例如,文科的学习过程可能更多依赖文本分析或讨论参与度,而非代码复杂度,如何设计可量化的多维度行为指标来适配不同学科的学习轨迹分析?
如果将文献中的LCA+SOM+序列挖掘的量化框架迁移到文科、商科课程时,可以保留以人为中心、过程导向的三维轨迹分析逻辑不变,只需要把编程专属的代码复杂度、提交次数等指标,替换为适配文科、商科的可量化行为与产出指标。学业表现维度可以沿用形成性与总结性成绩并做三分类,行为投入维度改用讨论发帖、阅读时长、作业时效,课堂互动等平台日志数据用于LCA聚类,过程产出维度以文科学术文本的句法复杂度、引用量、观点深度或商科案例报告的逻辑完整性、数据支撑度,方案可行性等指标,替代代码指标用于SOM降维聚类,再通过序列挖掘追踪学习状态跃迁与轨迹差异,即可实现跨学科的学习轨迹精准分析。
认真学习后收获特别大!一开始梦瑶分享我觉得和我的那篇很相似。我也对比了一下,我自己的理解是:这篇文章的方法更偏向 “状态 — 序列 — 分型”,以离散状态、行为顺序、多维度过程数据为核心,先划分学习状态,再看状态怎么转移,最后聚类出轨迹类型;而我的那个LGMM是“连续增长 — 潜类别混合”,以连续变量的增长曲线为核心,直接用截距、斜率拟合变化趋势,再分出不同增长轨迹类群。大家都是去区别出个性的学习者,相比与传统的整个班级的成绩提升,还是很个性化的。
这篇论文的独到之处在于将超位理论贯穿ENA编码框架,实现了从可视化描述到理论验证的跨越,使ENA成为拓展社会学理论的方法论载体。在面向中小学课堂教学的研究中,或许可以借鉴这类范式追踪学生从实验操作者到证据评估者的身份演进,将人机关系编码拓展至AI作为可质疑对象等维度
这篇研究通过潜类别分析、自组织映射与序列挖掘的组合,实现了对学习者全学期状态转移的精细刻画。研究发现也进一步回应了我最近关于学习投入是否能促进学习结果的困惑,即学习投入与成绩的正相关关系并非普适。过程导向的纵向追踪方法可迁移至STEM跨学科学习情境,用以识别不同类型学生的认知启动差异与学习模式分化,进而为差异化教学干预提供动态依据。