
- 导语
在教育干预研究中,标准做法是将干预与学生的前测分数交互,来检验对不同基础的孩子效果是否一样。但有一个根本性的问题几乎被所有人忽略了:当你在总分上发现“效果随前测能力变化”的模式时,这究竟是因为干预确实对能力不同的学生产生了不同影响,还是仅仅因为这套测验题中较易的题目正好受到了干预的更大影响?一项研究从方法论层面证明,这两种截然不同的解释会产生完全相同的统计数据,传统方法根本无法分辨。基于此,他们将项目反应理论(IRT)引入因果推断框架,利用题目层面的作答数据成功拆解了这两个效应。该方法在一项二年级阅读干预数据上的应用更是给出了一记警示——一个看似显著的“基础好的学生受益更多”的结论,实际上完全是“题目易难度”造成的假象。
- 方法的基本信息
方法类别及名称:在因果推断框架中结合项目反应理论(IRT),利用题目层面数据区分“因人而异的处理效应”与“因题而异的处理效应”。
- 核心思想:该研究揭示了一个致命的统计混淆问题:依赖总分进行的传统HTE分析,无法区分“干预效果确实因前测能力而变”和“干预效果与题目易难度相关”这两种根本不同的数据生成过程。
- 独特价值:它挑战了教育研究中“用总分做交互=检验异质性”的默认操作方法;最反直觉的警示在于——“基础好的孩子受益更多”的结论可能只是那套测验里简单的题目被干预效果放大后的人造结果。
- 关键产出:从方法论上准确识别出两种效果混淆的根源,并通过模拟和真实数据验证了问题的普遍性。
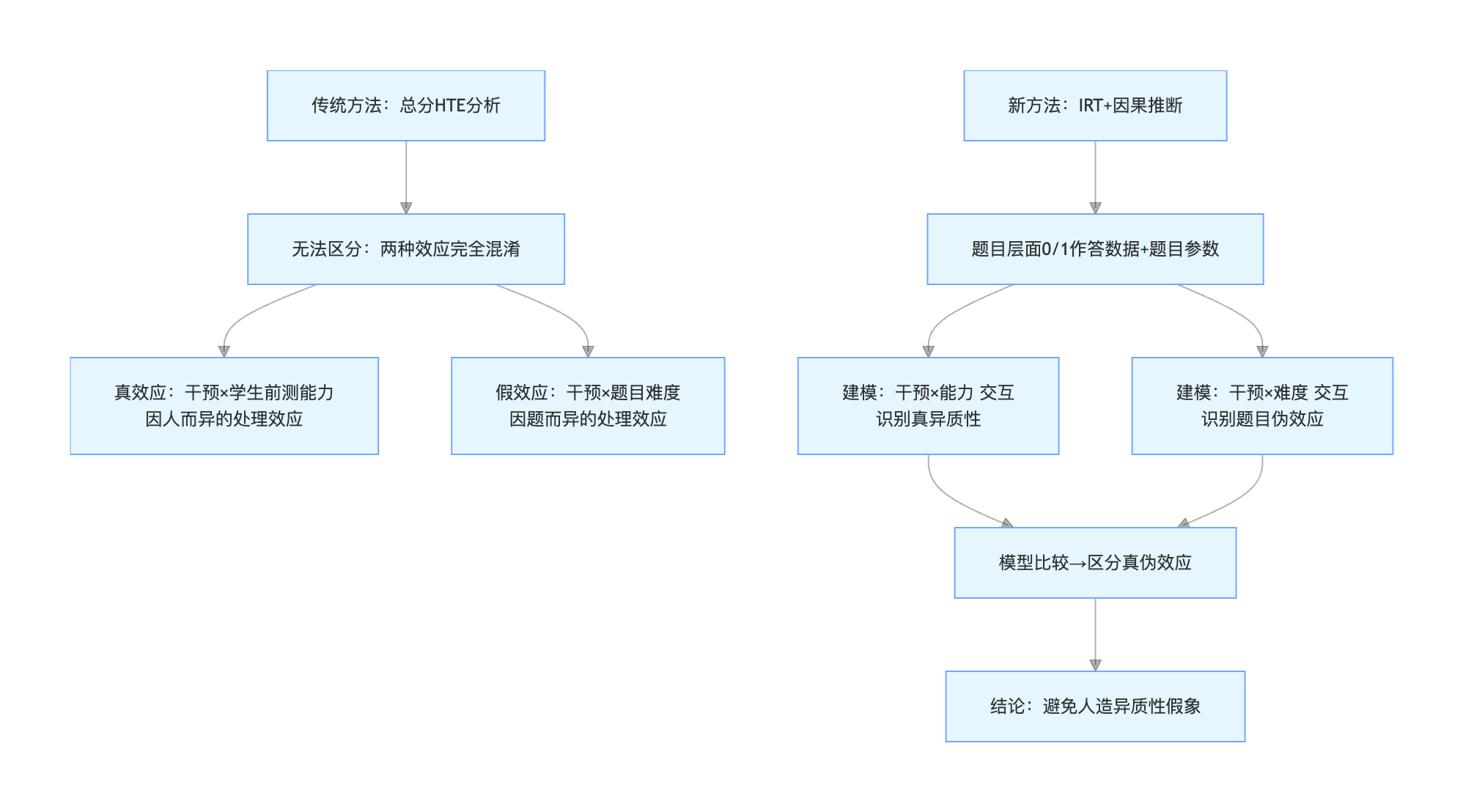
- 方法的操作过程
该方法的核心是放弃基于总分的分析思路,转向利用题目层面的作答数据,通过以下步骤来诊断和区分真正的异质性。
- 数据要求:除传统实验数据外,必须获取每个学生在每个题目上的作答记录(0/1得分矩阵),以及基于IRT模型估计出的题目参数(如难度、区分度)。
- 建模“人依赖”的异质性效应:建立包含“干预状态 × 前测能力”交互项的IRT模型。这个交互项捕捉的是处理效应随学生个体特征(前测能力)的变化。
- 建模“题依赖”的异质性效应:建立包含“干预状态 × 题目难度”交互项的IRT模型。这个交互项捕捉的是处理效应是否随题目本身的特征(易难度)而变化。
- 模型比较与选择:同时拟合上述两个模型(以及它们的组合),通过统计检验(如似然比检验、信息准则)比较它们对数据的拟合优度,判断哪种效应更能解释观测到的数据模式。
- 结果解读:如果“干预×前测能力”模型显著优于“干预×题目难度”模型,可以初步确认异质性源于学生层面;反之则提示处理效应可能仅是特定题目在难度或内容上的“局部效果”。该方法不是普通的加权或回归调整,而是一种模型选择式的识别策略。

- 方法的应用启示
适用情境:
- 任何使用标准化测验或量表分数作为结果变量的教育干预研究;
- 在干预效果异质性分析中发现了显著但难以解释的交互作用;
- 特别适用于题库公开、题目参数已知的测评场景(如PISA、TIMSS等国际大型测评)。
个人思考:我以前没有考虑过作者提出的问题,因此,该论文最让我震动的地方就是这样一个事实——我们可能在无意中报告了许多“子虚乌有”的异质性结论。方法的严谨性,决定了我们讲故事的可信度。
值得探讨的新问题:该方法是否也能用于分析更复杂的多维度测验?研究者能否通过什么方法规避这种混淆?
- 论文基本信息
Gilbert, Joshua B., Luke W. Miratrix, Mridul Joshi, and Benjamin W. Domingue. (2024). Disentangling Person-Dependent and Item-Dependent Causal Effects: Applications of Item Response Theory to the Estimation of Treatment Effect Heterogeneity. (EdWorkingPaper: 23-881). Retrieved from Annenberg Institute at Brown University: https://doi.org/10.26300/6b7w-vp07
渝晴对“干预效果因人而异可能只是题目障眼法”这一核心洞见的提炼非常精准,尤其是点出传统总分交互分析无法区分人依赖与题依赖效应这一致命混淆。顺着这个思路,如果将该方法迁移到多维度测验(如PISA的数学素养包含内容领域和认知过程两个维度),研究者是否需要先对每个维度分别估计题目参数,再构建多维IRT模型来同时捕捉人与题的交互?这或许能进一步检验异质性究竟是源于学生能力还是特定维度下的题目特征。
确实,我认为需要先对各维度分别估计题目参数,再纳入多维IRT模型同时估计。这样能区分异质性源于学生能力分布差异(人依赖)还是特定维度题目特征(题依赖),从而更精准检验“干预效果因人而异”究竟是能力结构所致,还是维度间题目属性的干扰。
这篇文章精准戳中了教育干预异质性研究的核心方法论漏洞。学界长期沿用的总分交互检验常规操作,根本无法区分干预效果真的因人而异和题目难度带来的统计假象,甚至会让完全虚假的异质性结论,变成看似严谨的学术成果。研究将项目反应理论与因果推断框架结合,通过题目层面的作答数据拆解两种混淆效应,不仅补上了该领域长期被忽略的方法短板,更给所有相关研究者敲响了警钟:任何研究结论的可信度,永远扎根在底层分析方法的严谨性之上。
看了这篇分享,我也思考一个问题,就是所谓的量化研究,数据说话,究竟代表了的是“谁”在发言?是否大样本的数据,可能还不如对一个个案的分析有价值?
不凑字数了,评论以表达我对这个结论和新视角的震惊,深受启发
这篇文章让我印象比较深的是,它提醒我们不能太轻易相信总分上的异质性结果。以前看到基础不同的学生干预效果不同,可能会直接解释为学生能力差异导致的,但文章指出这也可能只是题目难度造成的假象。把IRT和因果推断结合起来,从题目层面重新分析数据,这个思路很有启发。它也提醒教育研究不能只追求显著结果,还要想清楚结果到底是从哪里来的,否则很容易把测验本身的问题误当成学生差异。
这篇文章,让我深受启发,在原来的实验方法上进行了改进,也说明了使用场景:特别适用于题库公开、题目参数已知的测评场景(如PISA、TIMSS等国际大型测评)。非常有借鉴意义,对我很有学术帮助。文章从方法论上准确识别出两种效果混淆的根源,并通过模拟和真实数据验证了问题的普遍性。作者说,方法的严谨性,决定了我们讲故事的可信度,该方法有借鉴性,作者的总结更是令人耳目一新,发人深省。